1. Project 시작하기
이클립스를 시작하고, workspace를 선택해주시면 welcome 화면이 표시되고 이걸 꺼주시면 아래와 같은 화면을 볼 수 있습니다.
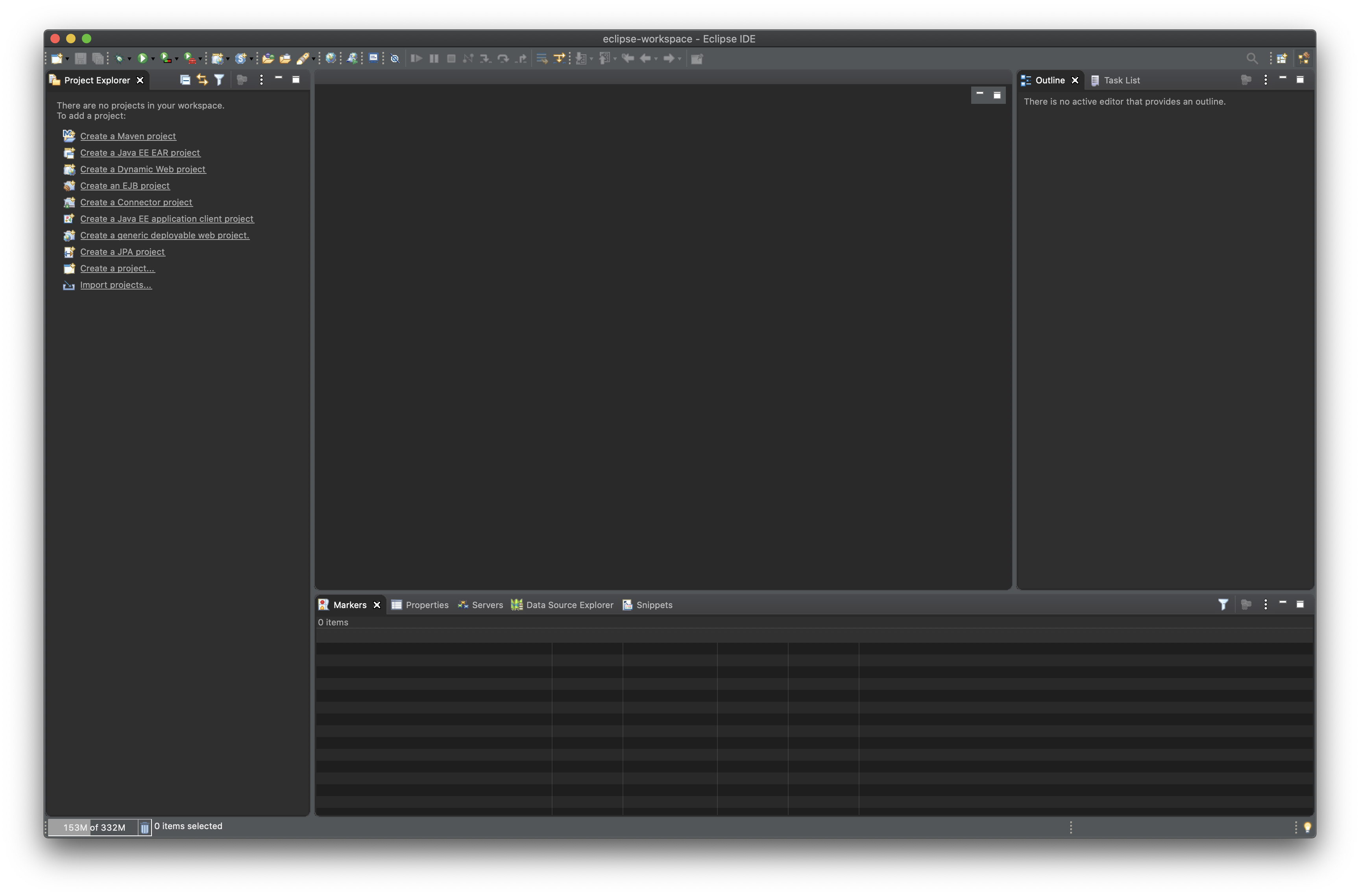
먼저 좌측에 Project Explorer라는 부분을 볼 수 있는데요.
기본적으로 하나의 프로그램은 Project 단위로 관리된다고 생각하시면 좋습니다. 하나의 Project 영역을 생성하고, 여기에 기본적인 코드부터 GUI를 위한 xml, 이미지 파일등 올려두고 관리합니다.
그럼 먼저 Project를 생성하겠습니다.
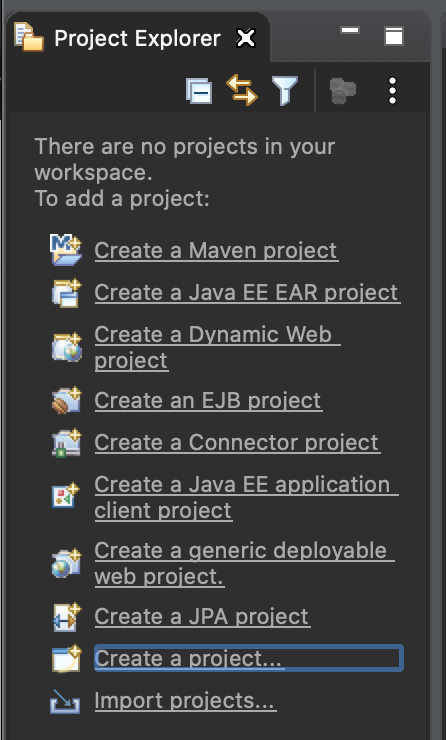
�
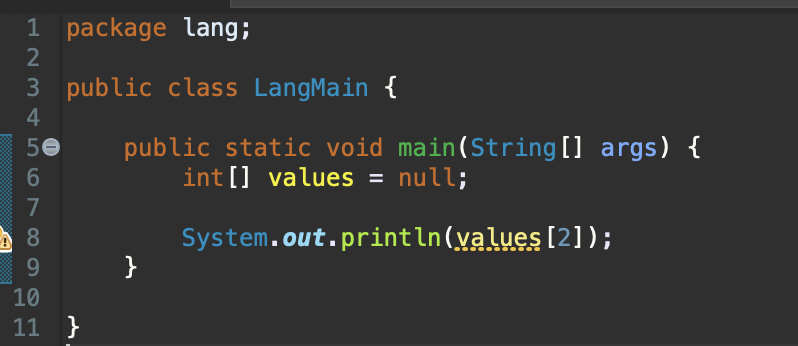
우측 Project Explorer 부분을 보게되면 다양한 용도를 위한 Project들이 존재하는 것을 볼 수 있습니다.
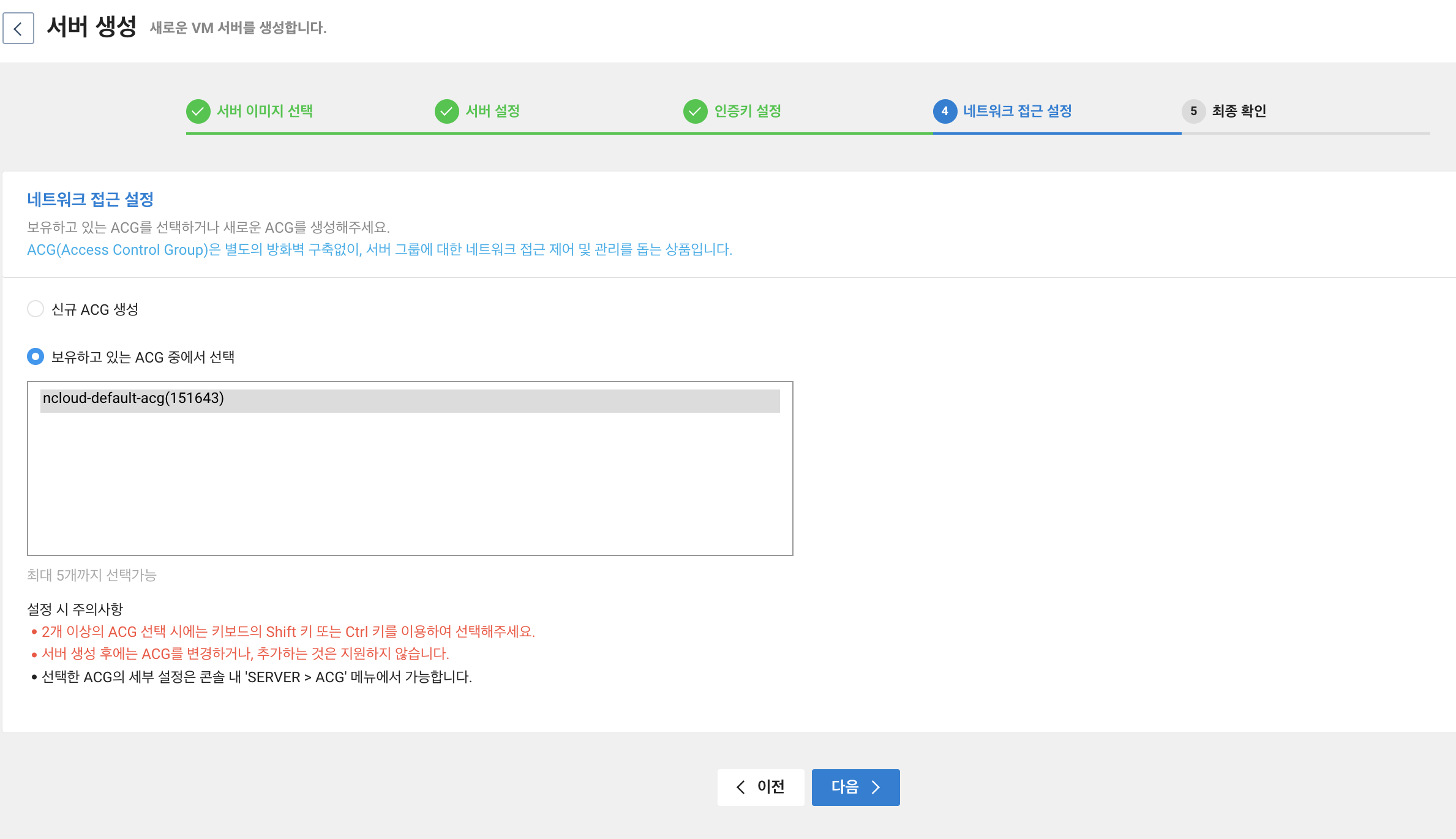
저희는 [Java Project]를 사용할 예정이기 때문에 [Create a project...] 라는 녀석을 눌러주세요.
그럼 아래와같이 New Project 라는 창이 등장합니다.
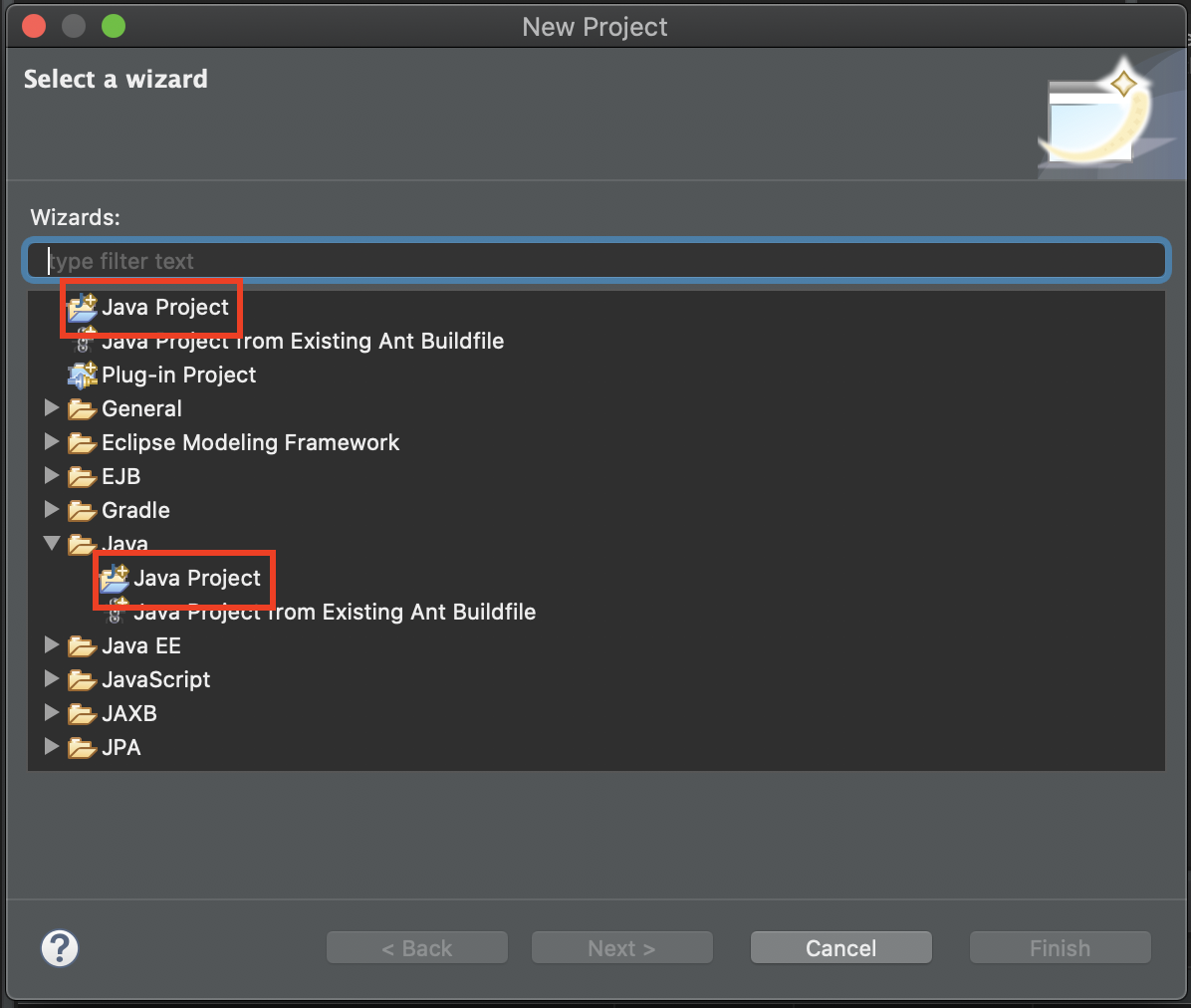
여기서 [Java Project]를 클릭해주세요. 그럼 아래와 같은 창이 등장합니다.
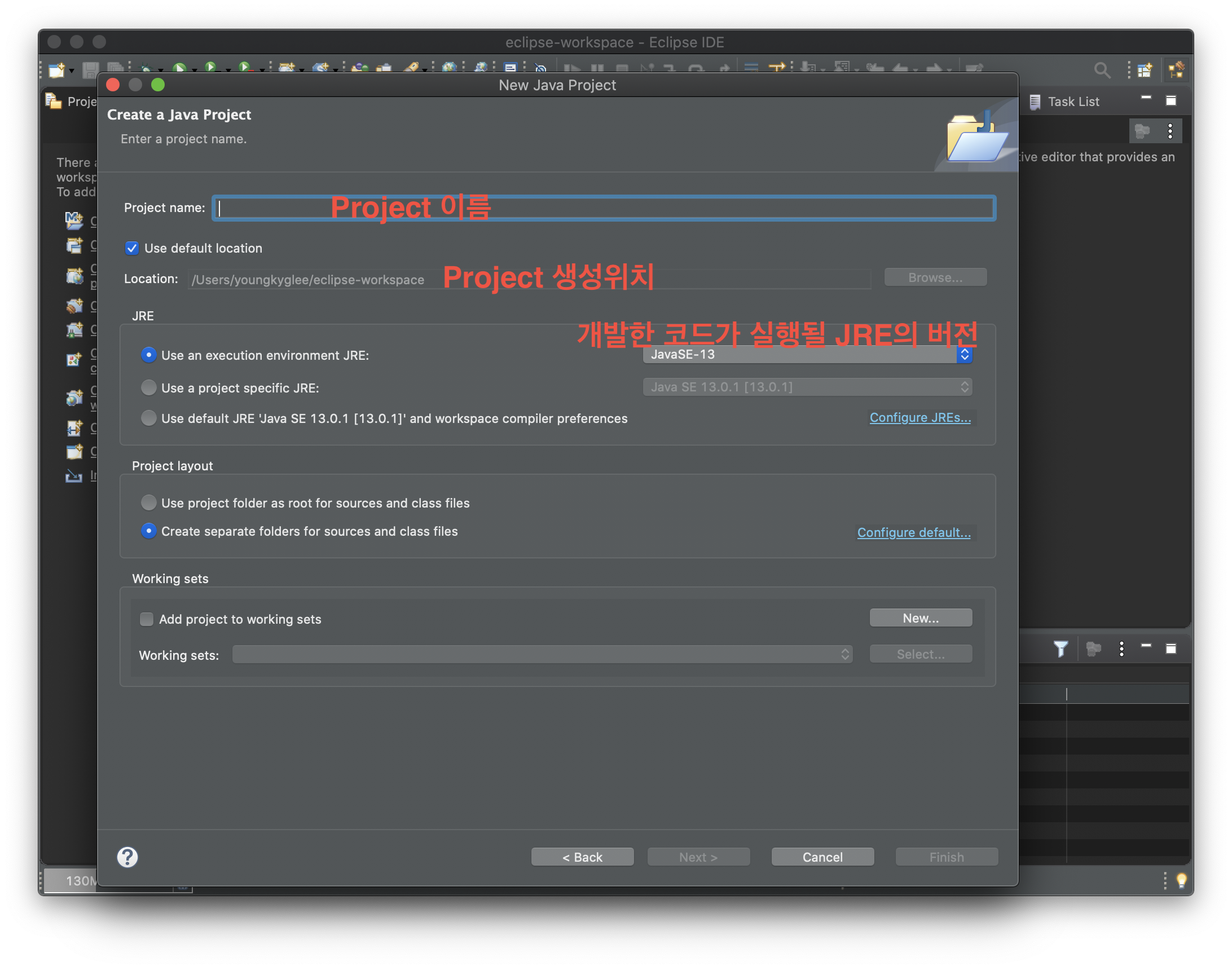
Project name에 원하는 값을 입력해보세요. 그럼 하단에 [Next]와 [Finish]가 활성화 됩니다.
[Next]를 눌러 다음으로 넘어가주시면, 몇가지 추가 설정이 있는데 여기서 모듈생성에 대한 부분을 아래와 같이 해제하신 후 [Finish]를 눌러주세요.

그럼 아래와 같은 창이 보입니다.

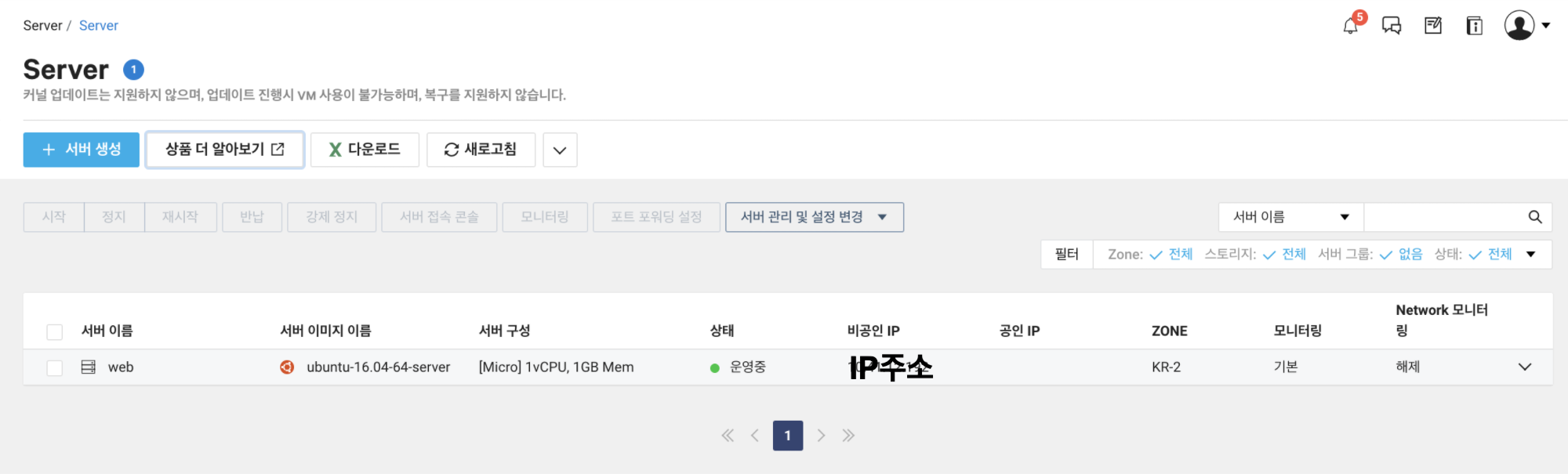
이렇게 Project를 생성했습니다. 다음으로 package를 만들겠습니다.
2. Package 생성
여기서 잘보시면 [Project Explorer] 라고 되어있던 부분이 [Package Explorer]라고 변경된 것을 볼 수 있습니다.
펼쳐보면 아래와 같은 상태가 됩니다.
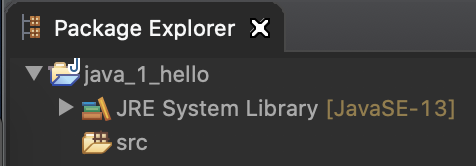
Package는 여러 코드들을 용도에 따라 구분해 정리하기 위한 폴더단위라고 생각하시면 좋을꺼같습니다.
Package를 'src'이하에 생성해 보겠는데요. Package 이름은 '소문자'를 사용하는게 약속입니다.
1) src 우클릭 -> New -> Package 클릭
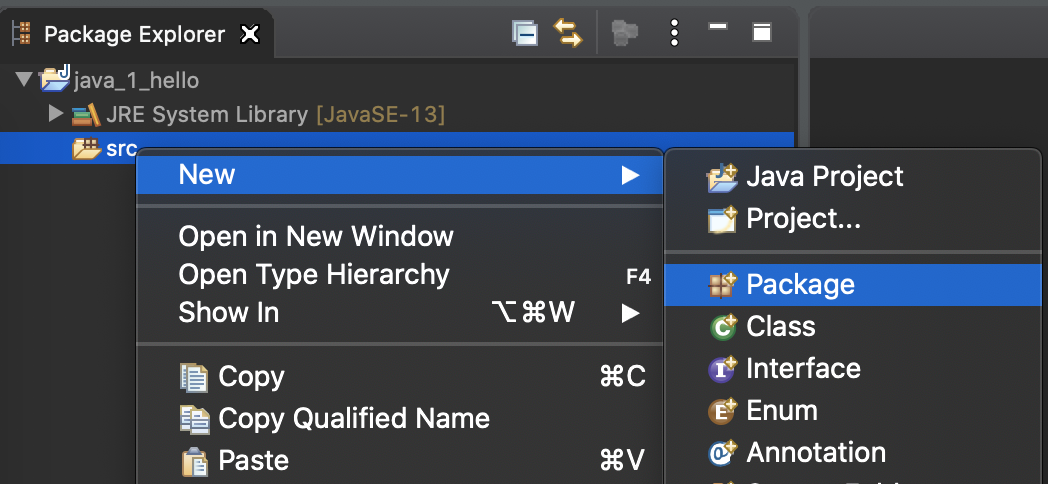
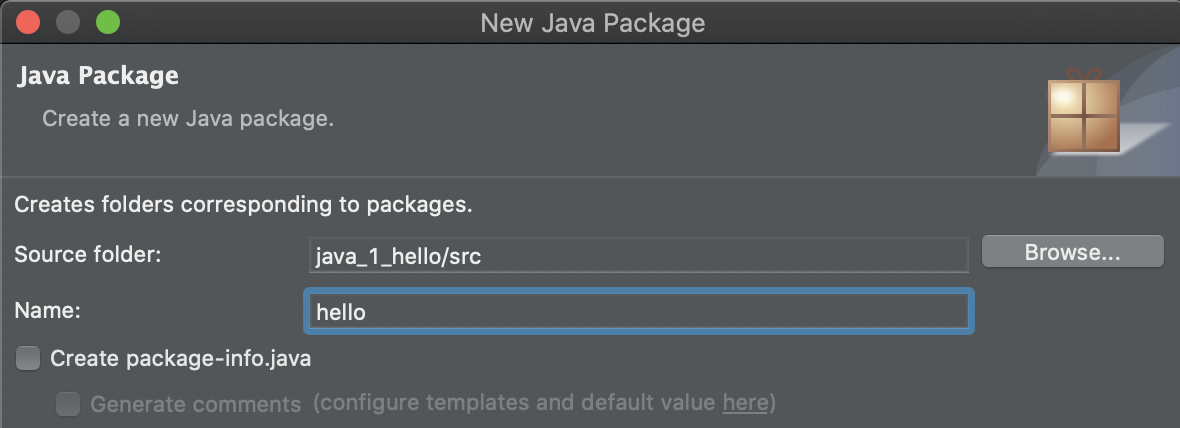
2) package 이름 입력(소문자쓰기) -> 생성
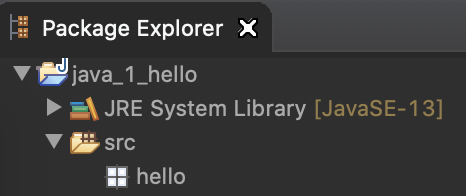
src 이하에 패키지 생성완료
3. Java Class 생성
Java는 Class 기반 언어라고 불립니다. 그렇기에 모든 코드는 Class라는 단위에서 작성되고 실행됩니다.
그렇기 때문에 흔히 C언어에서 'Main'이라고 부르는 부분 역시도 Java에서는 Class로 정의됩니다.
Class 생성을 해보겠습니다.
Class의 이름은 '대문자'로 사용하는게 약속입니다~!
1) 패키지 우클릭 -> New -> Class
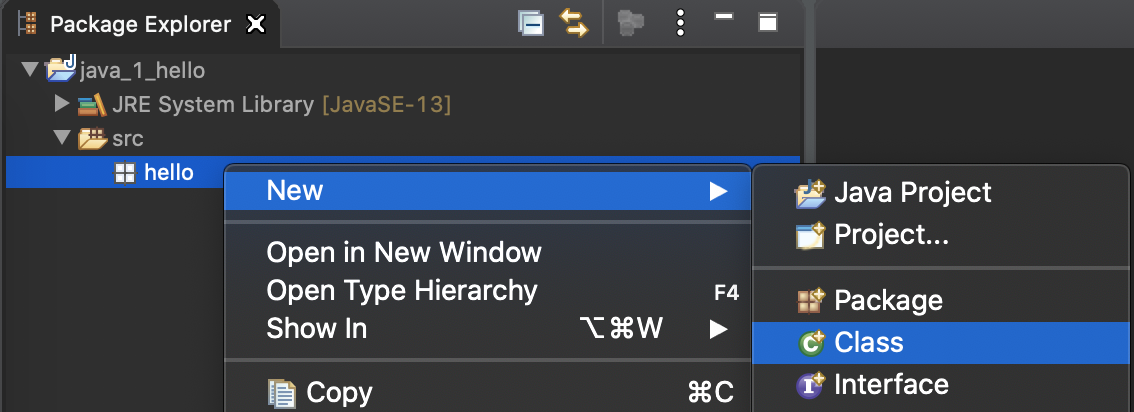
2) Class 이름 입력(클래스는 대문자) -> [public static void main(String[] args] 선택 -> Finish
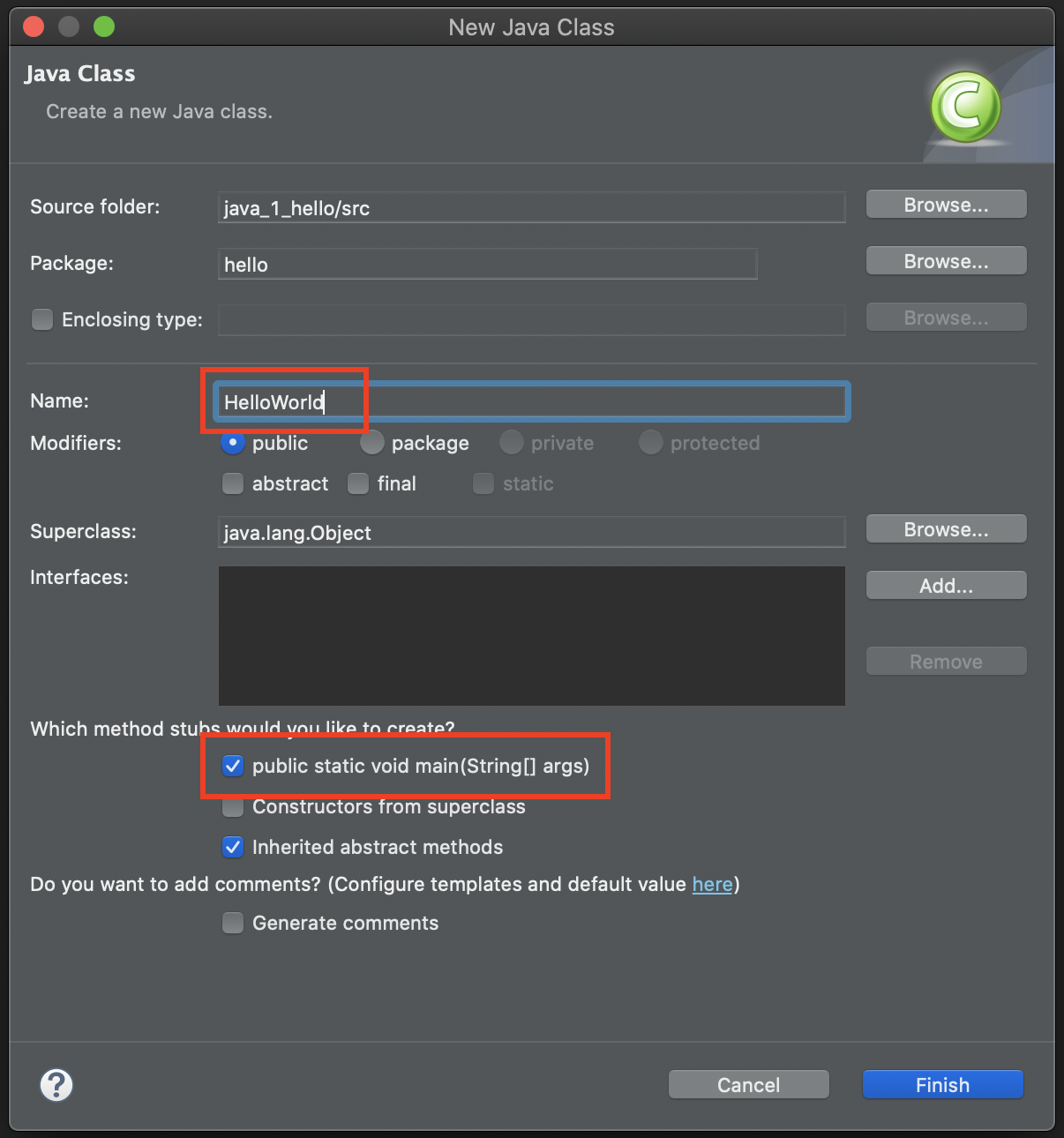
public static void main(String[] args) create 는 해당 클래스에 main 영역을 생성한다는 의미로 생각하시면 됩니다.
3) 패키지 아래 HelloWorld.java 클래스 생성 완료
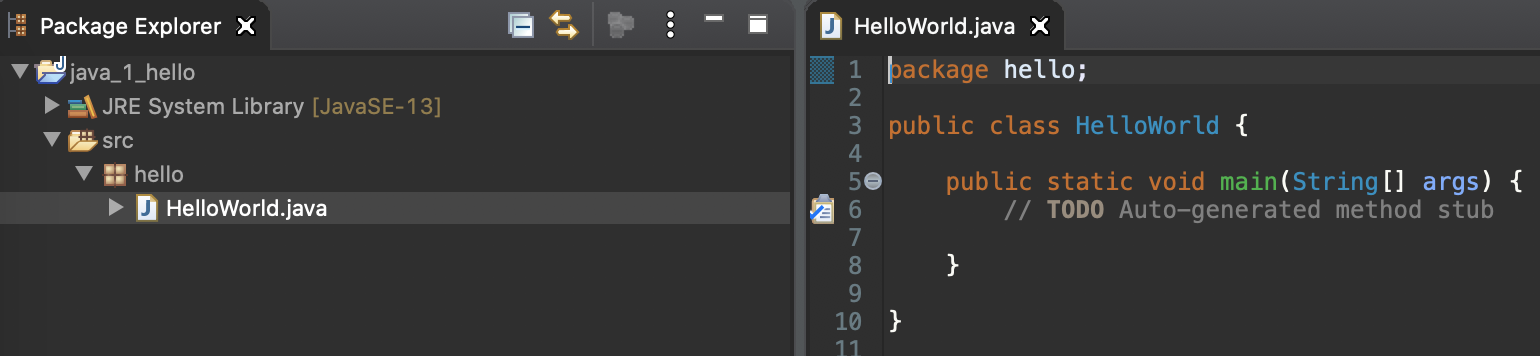
4. Hello World 출력하기
Java에서 print는 왜 이렇게 길까... 라고 종종생각합니다.
아래 코드를 봐주세요.
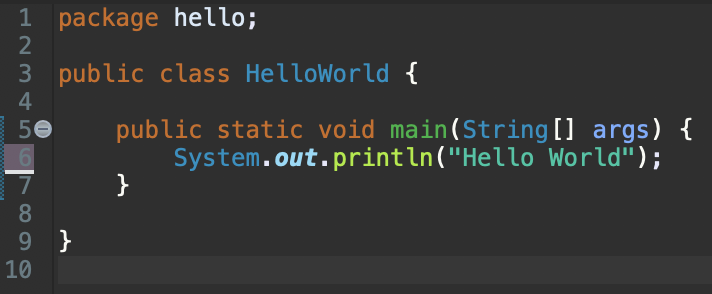
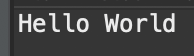 실행화면
실행화면
겨우 Hello World를 출력하는데도 앞에 System.out 이라는 녀석들이 붙습니다.
printf, print 등에 익숙했던 입장에서는 불편하게 보일 수 있습니다.
하지만, 나중에보면 이게 꽤 직관적이여서, 구문을 이해하는데 유용할 때도 있습니다.
Java라는 녀석도 코딩을 한 후 '컴파일'이라는 과정을 수행해야 실행할 수 있는 상태가됩니다.
이클립스에서는 여기에 대해 편리하는 기능을 제공하는데요.
바로 사용자가 코드를 [저장]하면 자동으로 컴파일을 수행하게됩니다.
때문에 코드를 작성하고 [저장] -> [실행]을 수행하면 별도로 컴파일을 수행하는 부분없이 코드가 실행됩니다.
만약 수정된 코드를 저장하지 않고 실행하면 아래와 같은 창이 뜨게 됩니다.
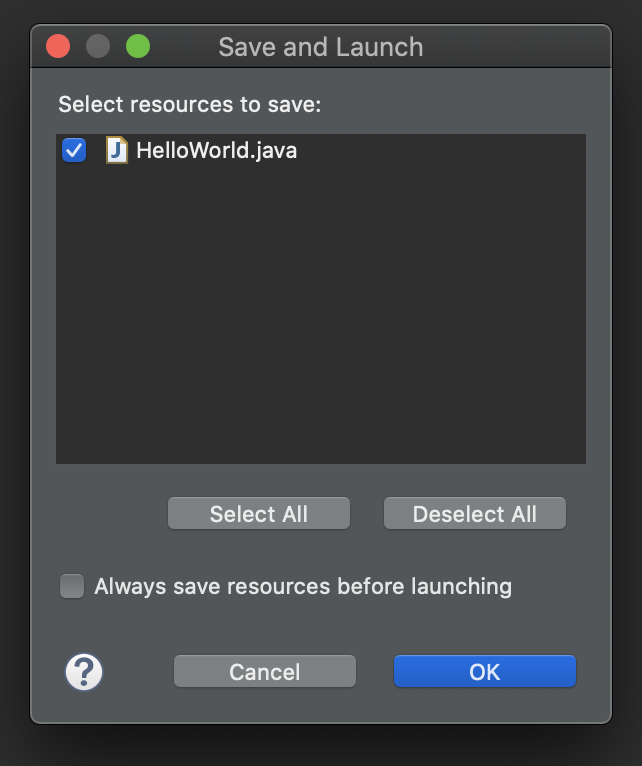
[ Save == 컴파일 ] 이라는 관점에서 보면, 이 창은
"컴파일을 수행하고 실행할까요?"
라는 의미를 갖습니다.
단, 혹시라도 실수로 Project에 Build Automatically를 해제한 상태라면, 위와같은 자동 컴파일이 수행되지 않습니다.
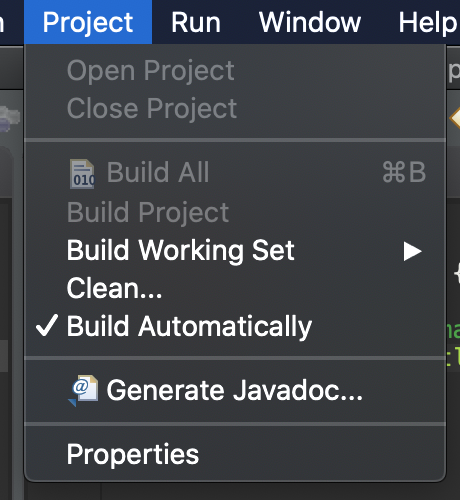
이클립스를 통해 프로그래밍의 시작인 "Hello World"를 출력해보았습니다.
이제 시작입니다~!