1. 시작전에~!
저번 포스팅 자료에서도 한번 언급드린것과 같이 아래 두 가지에 대한 조치가 필요합니다.
1) HTTP 통신을 함에따른 접속 암호 및 정보 유출
2) 우분투 유저가 분리되지 않아 발생하는 강력한 권한
각각에 대해서, 조치하지 않을 경우 어떤 문제가 있는지와 어떻게 조치할 것인지를 다루겠습니다.
2. HTTP대신 HTTPS로 설정하기
흔히 HTTP는 보안에 취약하다는 말이 많이있습니다. 먼저 왜, 취약한 것인지를 실제로 확인해보고 이 후 HTTPS로 Code-Server를 다시 구성한 후 차이점을 보겠습니다.
2.1 HTTP 통신 확인하기
HTTP 통신은 쉽게생각해서 평문전송이라고 생각하면됩니다. 웹브라우저에 입력되는 값을 별도의 암호화없이 전송하게됩니다.
만약 여러분이 카페에서 서버에 VS Code-Server에 접속하여 코딩을 하고있다고 가정해보겠습니다. 그리고 누군가가 카페에 설치된 공유기를 해킹한 상태라고 가정해보겠습니다.
(많은 카페들이 공유기 관리자 비밀번호를 수정하지 않은 상태로 사용하는 경우가 많기 때문에, 취약한 경우가 많습니다.)
해커는 공유기를 통해 연결된 모든 장비(노트북, 스마트폰 등)들의 통신데이터를 감시할 수 있습니다.
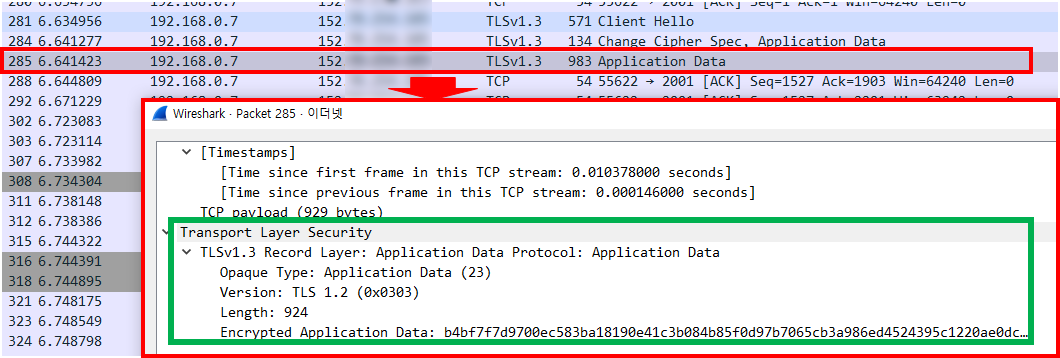
위 상황을 가정하고, 와이어샤크를 통하여 제 PC가 VS Code-Server가 설치된 오라클 클라우드와 통신하는 내용을 뽑아보겠습니다.

위와같이 실제로 전송되는 피킷을 열어보면 친절하게 [패스워드는 ~~~~입니다.]라고 전송하고있는 것을 볼 수 있습니다. 내용을 보시면 아시겠지만, 접속 URL과 Port는 물론이며, Form 데이터에 Item name까지 친절하게 적혀서 전송되기때문에, 해커입장에서는 특정한 값들로만 필터링을 걸어두고 기다리고 있으면 사용자들이 전송하는 다양한 정보들을 쉬득할 수 있는 구조입니다.
만약 해커가 password 라는 값 하나로만 필터링을 걸어두고 기다리고 있었다고한다면, 여러분이 VS Code-Server에 접속하는 순간 해커가 서버의 IP와 Port, 그리고 패스워드까지 알게되고 손쉽게 접근할 수 있게됩니다.
2.2 HTTPS로 구성하기
위와같은 문제가있기 때문에, 대부분 이러한 서비스를 제공하는 프로그램들은 HTTPS를 이용하여 통신을 할 수 있도록 지원하고있습니다.
일반적으로 HTTPS를 사용하기 위해서는 먼저 '인증서'라는 것이 필요합니다.
여기서 조금 고민을 했습니다. CA(인증기관)를 통하여 저희서버에서 발급한 인증서가 맞다는 것을 공증받는 형태로 진행할지, 아니면 그냥 사설인증서를 통하여 구성할 것인지...
사용자 입장에서는 후자와 같이 사용할 경우, '신용할 수 없는 인증서입니다'와 같은 메시지가 브라우저 상단에 뜨게됩니다.
고민해봤는데, 일단은 목적이 '개인용'이기 때문에, 이부분은 별도 CA등록없이 진행하도록 하겠습니다. 이부분에 대해서 불편함이 있다면, 추후 내용을 추가하거나 수정하도록 하겠습니다.
VS Code-Server에서 HTTPS 통신을 하는 방법은 간단합니다.
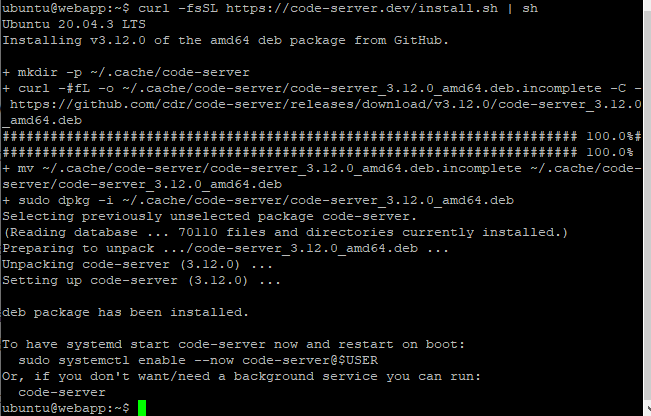
code-server 환경설정 파일에 들어가서 "cert: true"로 변경해주면 자동으로 VS Code-Server가 실행될 때, 파일을 생성합니다.
sudo vi ~/.config/code-server/config.yaml
위와같이 수정 후 code-server를 실행하면 crt파일과 key파일을 생성하면서, 알아서 https로 Code-Server를 실행합니다.
아래와 같이 말이죠.

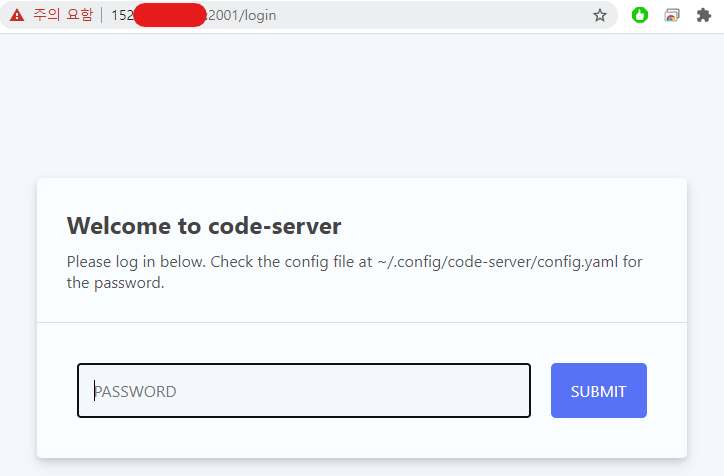
앞서 말씀드린것 처럼, 인증받지 못한 사이트이기 때문에 웹브라이저에서 경고창이 먼저 뜰 수 있습니다. 무시하고 연결해주시면 됩니다~ㅎ
이렇게 해주시고, 다시 와이어샤크로 데이터를 확인해보면, 아래와같이 데이터가 암호화되어 전송되고있는 것을 볼 수 있습니다.
(모든 웹 데이터가 암호화되기 때문에 실제로 저 데이터가 Password를 암호화한 값인지도 확인이 불가능합니다.)
이런식으로 암호화해서 전송되기 때문에, 혹시라도 전송되는 패킷데이터가 제 3자에게 노출되어도 안전하게 통신이 가능합니다.
3. User 분리하기
처음 기본으로 제공되는 ubuntu라는 계정은 sudo 권한을 갖고있는, 강력한 유저입니다.
때문에, VS Code-Server에 접근하여, 터미널(메뉴>터미널>새터미널)을 실행하면 이 강력한 권한을 사용할 수 있습니다.

위 처럼, 간단하게 root 권한을 취득할 수도 있습니다. 서버의 주인이 바뀌는 순간이죠...
이러한 문제를 해결하기 위해서, sudo 권한이 없는! VSCode를 위한 유저를 만들어줍니다.
sudo adduser (유저명)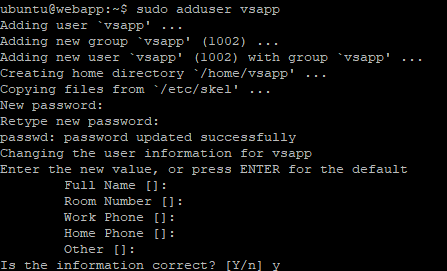
저는 위처럼 vsapp라는 유저를 만들었습니다. 유저정보는 공백으로 만들었고요. 그리고 해당 유저로 변경한 후 해당 유저의 홈 디렉토리에서 code-server 명령을 수행해보았습니다.
sudo su vsapp # 유저 변경(ubuntu > vsapp)
cd # vsapp의 홈디렉토리로 이동(/home/vsapp)
code-server # code-server 실행결과는 아래와 같습니다.

보시는것처럼, 마치 Code-Server를 처음 실행한거 같은 상황입니다.
넵, 맞습니다. 해당 홈 디렉토리는 새로 만들어졌고, 여기에는 설정파일은 물론이고, 좀전에 만든 인증서 파일들도 없습니다 ㅎㅎ
저번 포스터에서 중간에 '여기까지만 따라해주시고, 이제부터는 다음 포스터까지 다 보시고 따라와주세요!' 라고한 이유입니다 ㅎㅎ...
혹시 그냥 따라오셨다면... 복습하는 마음으로 설정파일을 수정해주세요~ ㅎㅎ
vi ~/.config/code-server/config.yaml
######### 설정파일 내용 ##########
bind-addr: 0.0.0.0:2001
auth: password
password: (사용자 암호)
cert: true그리고 다시 실행해준 후, 터미널에서 명령어를 실행하면~!

위와같이, sudo권한이 없기때문에, 실행할 수 없다는 결과가 뜨는것을 볼 수 있습니다.
물론 막 생성된 계정이고, 별도의 권한도 없기 때문에, 해당계정으로는 타 소유주의 파일을 수정/삭제는 물론 폴더에 임의로 파일을 생성하는 것도 불가능합니다.
이렇게한다면, 조금은 안전하게 저희 서버를 지킬 수 있을꺼에요... ㅎㅎ
여기까지해서 VS Code-Server 구축부분은 일단 마무리하겠습니다.
다음에는 슬슬 지루하니, 파이썬+Flask를 이용해서 홈페이지 띄우는 부분을 다뤄보겠습니다~!
감사합니다.
'취미코딩 > WEB' 카테고리의 다른 글
| [개인용 클라우드 웹] 2. 클라우드 VSCode Server 구성 (0) | 2021.09.24 |
|---|---|
| [개인용 클라우드 웹] 1. 오라클 클라우드 설정 (3) | 2021.09.22 |