Pandas 라이브러리에 대한 간단한 소개와 몇 가지 자주 사용되는 기능에 대해서 정리합니다.
1. Pandas?
파이썬에서 데이터 전처리를 할 때 가장 많이 사용되는 라이브러리 중 하나입니다.
Pandas라이브러리의 기본은 DataFrame이라는 구조에서 시작됩니다.
DataFrame(데이터 프레임)은 Excel과 같은 표로 된 형태로 데이터를 관리합니다. 아래 샘플 코드를 봐주세요.
import pandas as pd
data = { 'Outlook' : ['Rainy', 'Rainy', 'Overcast', 'Sunny', 'Sunny', 'Sunny',
'Overcast', 'Rainy', 'Rainy','Sunny','Rainy','Overcast',
'Overcast','sunny'
],
'Temp' : ['Hot','Hot','Hot','Mild','Cool','Cool','Cool','Mild','Cool',
'Mild','Mild','Mild','Hot','Mild'],
'Humidity' : ['High','High','High','High','Normal','Normal','Normal',
'High','Normal','Normal','Normal','High','Normal','High'],
'Windy' : ['False','True','False','False','False','True','True','False',
'False','False','True','True','False','True'],
'Playgolf' : ['No','No','Yes','Yes','Yes','No','Yes','No','Yes','Yes','Yes',
'Yes','Yes','No']
}
df = pd.DataFrame(data)
폴더에 쌓인 많은 자료들중 아무 데이터나 갖고 와 봤습니다.
위의 코드를 보면, data라고 정의된 부분을 보면, key로 Outlook, Temp, Humidity 등이 설정되어있고, 리스트 형태의 Value들이 존재하는 것을 볼 수 있습니다.
그리고 이렇게 만들어진 data를 Pandas에 DataFrame으로 넣어주는데요. 이렇게 만들어진 데이터 Frame을 보면 아래와 같습니다.
 DataFrame
DataFrame
보게 되면, Dict의 Key에 해당하는 부분이 Column으로 오게 되고, Value에 해당하는 내용들이 순서대로 0~13까지 들어간 것을 볼 수 있습니다.
이러한 형태의 데이터를 Pandas의 DataFrame이라고 부릅니다.
2. 자주 사용되는 함수들
Pandas에서는 많은 함수들을 제공합니다. DataFrame에 들어있는 데이터들을 쉽고 빠르게 핸들링하기 위함이죠.
주의할 점은 동일한 결과를 위한 함수라도 사용방법에 따라서 속도가 수십 배씩 차이가 날 수 있습니다.
특히 핸들링하는 데이터의 크기가 수백GB이상이되면 그 차이에 따라서 단 몇 분이면 끝나는 작업이 며칠이나 걸리는 경우도 허다합니다.
따라서 많은 기능들을 알고 적절하게 사용하는 게 중요합니다.
먼저 원하는 데이터들을 찾아내는 필터링에 대해서 정리하겠습니다.
- 특정 Column 선택하기
- df[ 'Humidity' ] : 특정 Column(Humidity)의 데이터들을 뽑아냅니다.(출력 형태 : Pandas Series)
- df[[ 'Humidity' ]] : 특정 Column(Humidity)을 뽑아냅니다.(출력형태 : Pandas DataFrame)
- df[[ 'Humidity, 'Outlook' ]] : 특정 Column들(Humidity, Outlook)을 뽑아냅니다.(출력형태 : Pandas DataFrame)
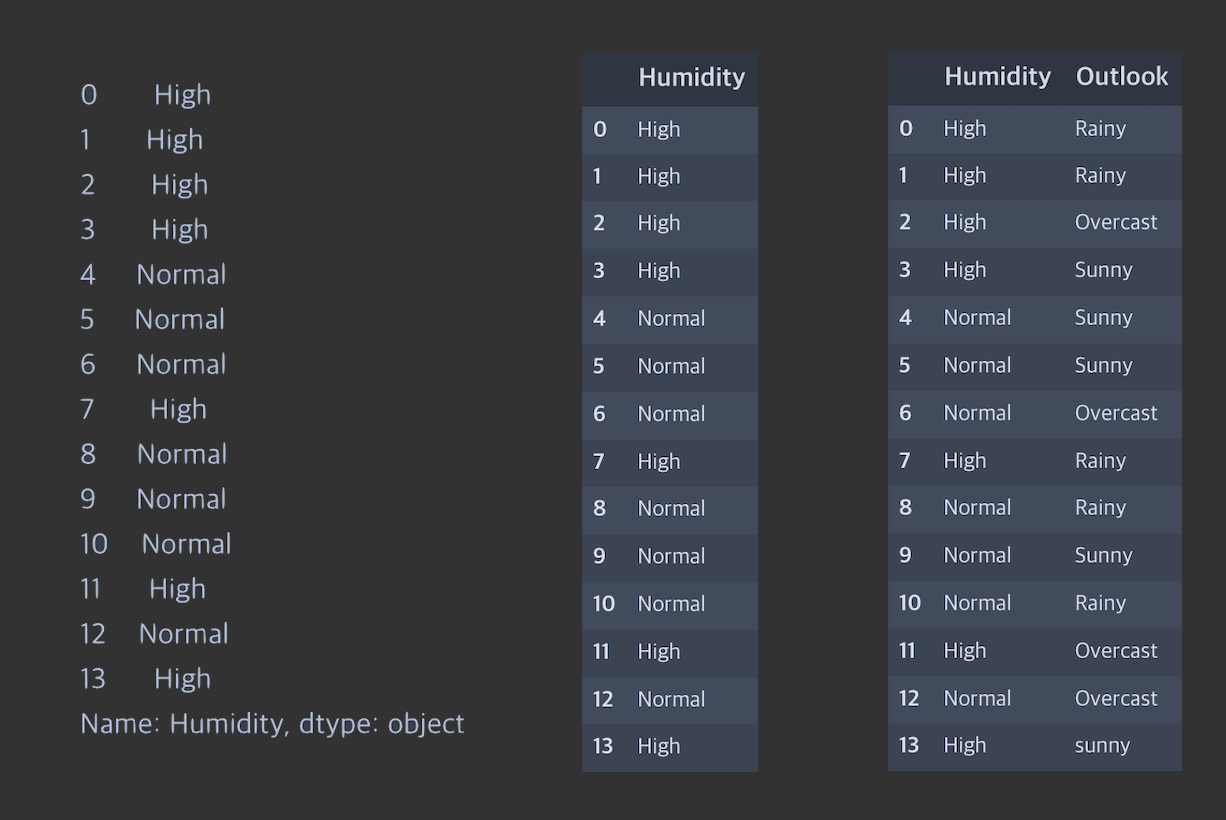 각가의 실행결과
각가의 실행결과
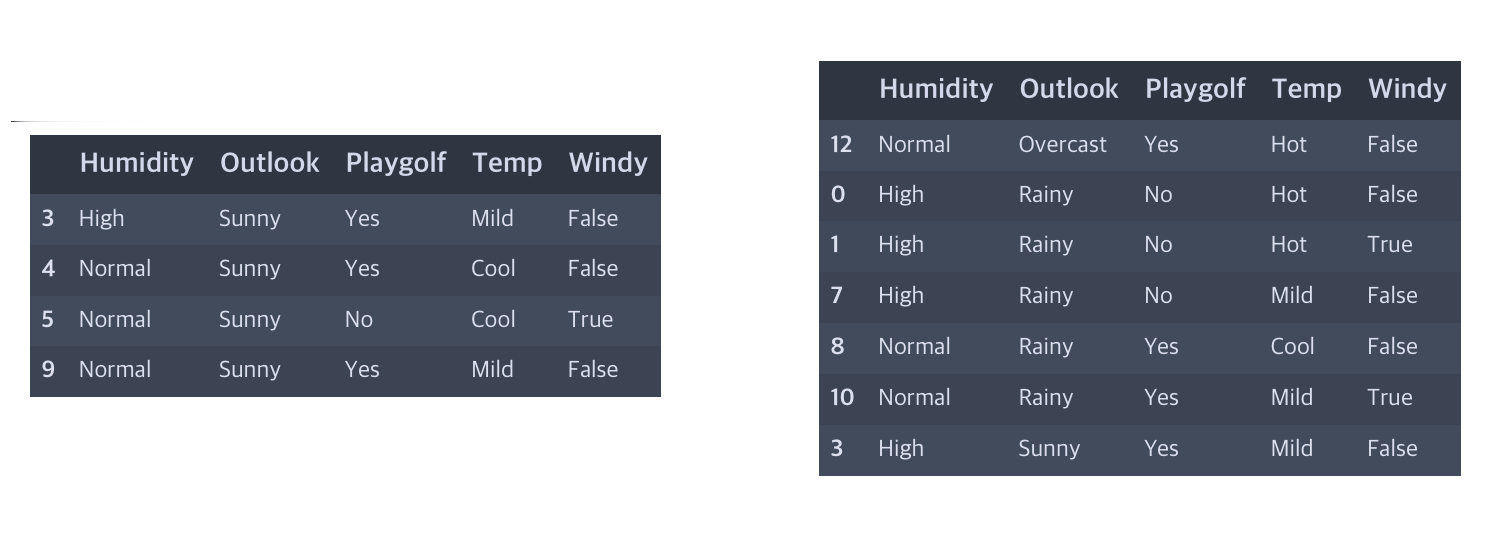
- 특정 Row 선택하기(loc, iloc)
DataFrame에서 Index는 DataFrame이 생성됐을 때 기준으로 설정됩니다. 따라서 중간에 Row가 삭제되거나, 새롭게 정렬하는 경우 Index번호가 순서대로 설정되지 않는 경우가 발생합니다.
따라서 특정 Row들을 뽑아낼 때, 이 Index로 뽑아내는 경우, 어떤 기준으로 뽑을지에 따라서 두 가지로 나눠집니다.
다음과 같이 Outlook Column을 기준으로 새롭게 정렬된 DataFrame은 Index의 순서가 섞여있는 것을 볼 수 있습니다.
 df.sort_values('Outlook')
df.sort_values('Outlook')
여기서 특정 Row를 선택해보겠습니다.
- df.sort_values('Outlook').loc[3:9] : Index번호가 3인 것부터 9인 것까지 출력합니다.
- df.sort_values('Outlook').iloc[3:9] : Index번호와 상관없이 3부터 9번 row를 출력합니다.(시작=0)
- 정렬(sort_index, sort_values)
- df.sort_index() : Index 기준으로 정렬을 수행합니다. (중간에 삭제된 Index들이 새로 생기지는 않습니다.)
- df.sort_values(by) : by에 해당하는 Column의 값을 기준으로 정렬합니다.
옵션
ascending = True(기본) / False : True는 오름차순, False는 내림차순 정렬입니다.
inplace=True / False(기본) : 정렬한 결과를 기존 DataFrame에 반영할지 여부입니다.
- reset_index
기존 DataFrame의 Index를 새로 설정합니다. 기존의 Index는 새로운 Column으로 만들어집니다.
drop = True 옵션을 적용할 경우 기존 Index가 새로운 Column으로 만들어지지 않고 삭제됩니다.
- T (Transpose)
Index와 Column의 위치를 바꿉니다.
 실행결과
실행결과
- astype(type)
특정 Column의 데이터 타입을 변경합니다.
df['Outlook'] = df['Outlook'].astype('str') 과 같이 사용 가능합니다.
주로 숫자 데이터가 문자로 되어있는 경우 int64나 float64로 변환합니다.
- dropna
DataFrame에서 특정 값이 비어있는 경우가 있습니다. 사람에 따라서 이것을 Null, NA, NaN, None 등 다양하게 부릅니다.
이러한 데이터는 숫자도, 문자도 아니기 때문에 특정값으로 변형하거나 삭제하는 작업이 필요합니다.
dropna는 이러한 값을 삭제해주는 함수입니다.
df.dropna() : 빈 값이 존재하는 Row를 제거합니다.
- drop
특정한 Column을 제거하는데 주로 사용됩니다.
df.drop(columns = '컬럼명')의 형태로 자주 사용합니다.
- fillna(value)
위에서 언급한 것과 같이 빈 값은 그대로 사용이 불가능하기 때문에, 다른 값으로 변경하거나 제거해야 할 필요가 있다고 말씀드렸습니다.
fillna(Value)는 이러한 빈 값을 특정한 Value로 대체하는 역할을 합니다.
- isnull
또또, 이 녀석은 데이터에 빈 값이 존재하는지 확인하는 용도로 사용됩니다.
빈 값은 True로 아닌 값은 False를 반환합니다.
따라서 보통 이것만 사용되는 경우는 거의 없고, 저는 주로 특정 컬럼에 빈 값이 몇 개나 있는지 등의 용도로 사용합니다.
df.isnull().sum()
sum은 원래는 컬럼별로 숫자들을 더해주는 역할을 하는데 컴퓨터에서 False = 0, True = 1로 값을 다루는 경우가 많다보니 위와같이 사용할 경우 컬럼별로 빈 값의 개수를 반환해주게 됩니다.
 x는 Null값만 존재하는 Column
x는 Null값만 존재하는 Column
- info
가장 중요한 녀석인데, 뒤늦게 나왔네요.
DataFrame의 정보를 요점 정리해서 보여줍니다.

위와 같이 각 컬럼에 대해서 Null 값의 개수와, 데이터 타입 등의 정보를 알려줍니다.
데이터를 불러오고 가장 먼저 사용하는 기능이며, 전처리가 끝난 후 최종적으로 확인하는 데 사용되는 기능이기도 합니다.
- columns
DataFrame의 Column 이름을 확인하거나 재정의할 경우 사용됩니다.
df.columns : 칼럼들의 이름 확인
df.columns = ['col1', 'col2' ~] : 컬럼명 재정의
- pd.concat( [ A , B ] )
DataFrame에 적용되는 기능이 아니라 pandas에 붙는 녀석임을 주의하시기 바랍니다.
이 기능은 둘 이상의 데이터를 연결하는 데 사용합니다.
여기서의 연결방식은 A데이터 아래에 B데이터를 붙이는 것으로 두 개의 DataFrame이 동일한 Column들을 갖고 있다는 가정에서 Row가 늘어나는 형태로 데이터가 늘어가게 됩니다.
- pd.merge( left, right, how='inner', on=None, left_on=None, right_on=None ~ )
정말 중요한 기능이어서 옵션들까지 몇 개 적었습니다.
SQL에서 Join을 생각하셔도 좋습니다. 실행 형태는 아래와 같습니다.
pd.merge( A, B ) : A와 B 두 개의 DataFrame에서 동일한 이름의 Column을 기준으로 병합합니다.
여기서의 병합은 A의 Column옆에 B의 Column을 추가하는 경우를 말합니다.
pd.merge( A, B, how='left' ) : how에는 left, right, inner의 3가지 경우가 사용됩니다.
left = A DataFrame은 그대로 둔 상태로 B를 붙입니다. 이때 맵핑되는 값이 없으면 Null 값이 생깁니다.
right = B를 기준으로 합칩니다.(위와 반대)
inner = 위의 결과 중 하나에서 null값이 존재하는 row를 제거한 형태입니다.
상세한 내용은 여기를 참고하세요.
https://datascienceschool.net/view-notebook/7002e92653434bc88c8c026c3449d27b/
Data Science School
Data Science School is an open space!
datascienceschool.net
일단 중요한 기능들은 이런 것들이 있습니다.
unstack이나 groupby 등 여러 가지 녀석들이 있지만, 이런 것들은 나중에 작업하면서 다시 다루겠습니다.