앞으로 진행될 거의 모든 내용에서 클래스를 다룰것 같습니다. 또한, 클래스에 사용되는 것들에 대해서만 언급해도 끝이 없습니다. 때문에 다음 내용부터는 대부분 [클래스의 ㅇㅇㅇ]이라는 느낌으로 진행될듯합니다.
1. 객체지향 프로그래밍 ( OOP : Object Oriented Programing )
사실 객체지향이라는 것에 대해서만 다뤄도 짧지 않습니다만, 간단하게만 집고 넘어가겠습니다.
객체지향 프로그래밍이 어떤 것이다라고 정의해둔 글들이 많이 있습니다만, 제 생각에 가장 간단하게 말하자면 아래와 같습니다.
객체지향 프로그래밍(OOP)은 프로그램이 사용하는 유관한 데이터들을 조합하여 묶어줌으로 객체(사물, 사람, 대상)를 만들어주고, 여기에 객체가 행할 수 있는 행동을 정의해줌으로써 각 객체가 상호작용을 수행할 수 있는 프로그래밍을 의미한다.
라고 생각합니다. 사람마다 생각하는것에 차이가 있기 때문에 제가 생각하는 객체에 대한 정의가 다른사람이 볼때는 잘못됬다고 생각할 수 있습니다.
어찌되었든 글로 표현하면 이해하기가 힘든 내용입니다. 때문에 간단하게 그림을 통해 알아보겠습니다.
먼저 객체의 정의가 필요합니다.
객체의 정의란, 어떤 객체가 취할수 있는 상태(state, 멤버변수)를 정의하고, 객체가 행할 수 있는 행동(Action, 멤버함수)을 정의하는 것입니다.
간단하게 사람이라는 객체를 정의한다고하면 아래와 같은 것들을 의미합니다.
여기서 중요한 것은 가변하는 값을 갖은 멤버 변수는 이에 대응하는 멤버 함수가 존재해야합니다.
예를들어 '몸무게'라는 멤버변수는 '식사하기'라는 멤버함수에 의해서 제어된다는 식의 개념이 필요합니다.
물론, 고정되는 값을 갖는 멤버변수도 존재합니다. 만약 위의 데이터가 한달만 사용되는 데이터라면, '나이', '성별'등은 특별한 경우가 아니라면 고정된 값을 갖은 멤버변수일 것입니다.
만약 위와같이 멤버변수, 멤버함수를 통해서 객체(=사람)을 정의했다면, 다음은 정의한 객체들을 구분할 이름을 할당합니다.
위와같이 각각의 이름을 할당받은 객체들은 앞서 정의한 기준에 따라 초기화를 해주게됩니다.
초기화는 각각의 객체가 갖고있는 상태를 저장하는 것을 말합니다. 예를들어 철수의 현재 나이는 7살이고, 키는 70cm, 몸무게는 20kg등의 정보등을 입력하는 과정을 말합니다.
객체의 초기화가 끝나면 각 객체들은 정의해준 멤버함수를 통해서 서로 상호작용이 가능합니다. 물론 단순히 자신의 값만을 변경하는 것도 가능합니다.
위와같은 과정을 이제 코드를 통해서 다뤄보겠습니다.
2. Class ( CPP/Class.cpp )
객체지향 프로그래밍(OOP : Object Oriented Programing)의 꽃 Class에 대해서 다뤄보겠습니다.
#include <iostream>
using namespace std;
class User{
private:
int age;
int tall;
int weight;
bool sex; // true: 남성, false: 여성
public:
void Init(int age, int tall, int weight, bool sex){
this->age = age;
this->tall = tall;
this->weight = weight;
this->sex = sex;
}
void prtInfo(){
cout << "age : " << age << endl;
cout << "tall : " << tall << endl;
cout << "weight : " << weight << endl;
cout << "sex : " << sex << endl << endl;
}
};
int main(void){
User Hun2, Chulsu;
Hun2.Init(7, 30, 20, true);
Chulsu.Init(7, 32, 22, true);
Hun2.prtInfo();
Chulsu.prtInfo();
return 0;
}
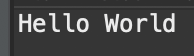
실행결과
정말 간단한 Class 예제입니다.
User라는 클래스를 보게되면 먼저 [ private 와 public ]이라는 두가지를 볼 수 있습니다. 바로 '접근제한자'라는 것입니다. 다음에 자세하게 다뤄보겠지만, 간단히 말하면 private는 해당 class내의 함수에서만 해당 변수들에 접근이 가능하다는 것을 말하며, public은 어디서든 해당 함수나 변수에 접근이 가능하다는 것을 말합니다.
private 로 선언된 부분에 멤버변수를 적어주었고, public으로 선언한 부분에 멤버함수를 적어주었습니다. private로 멤버변수에 접근하지 못하게 하는것을 '정보은닉'이라고 합니다. 굳이 사용자가 알아야할 정보가 아닌것에 접근하는것을 차단하기 위한 방법이죠.(접근제한자 설명시 다시 언급하겠습니다.)
다음으로 this라고 되어있는 부분을 볼 수 있습니다. 'this'는 현재 접극하는 객체의 주소값을 갖고있는 녀석을 말합니다.
만약 '훈이'라는 객체가 만들어지고 해당 객체에서 'this'가 포함된 함수를 실행하면, 거기서 'this'는 훈이라는 객체의 주소가됩니다. 따라서 [this->변수]를 통해서 해당 객체가 갖고있는 멤버변수에 접근이 가능합니다.
따라서 위의 Init부분을 보게되면 같은 age라는 변수명을 사용했음에도 서로 구분되어 사용이 가능하게됩니다.
앞에서 동적할당에 대해서 간단하게 말씀드렸습니다. 여기서는 메모리와 연결해서 조금 더 자세하게 알아보도록 하겠습니다.
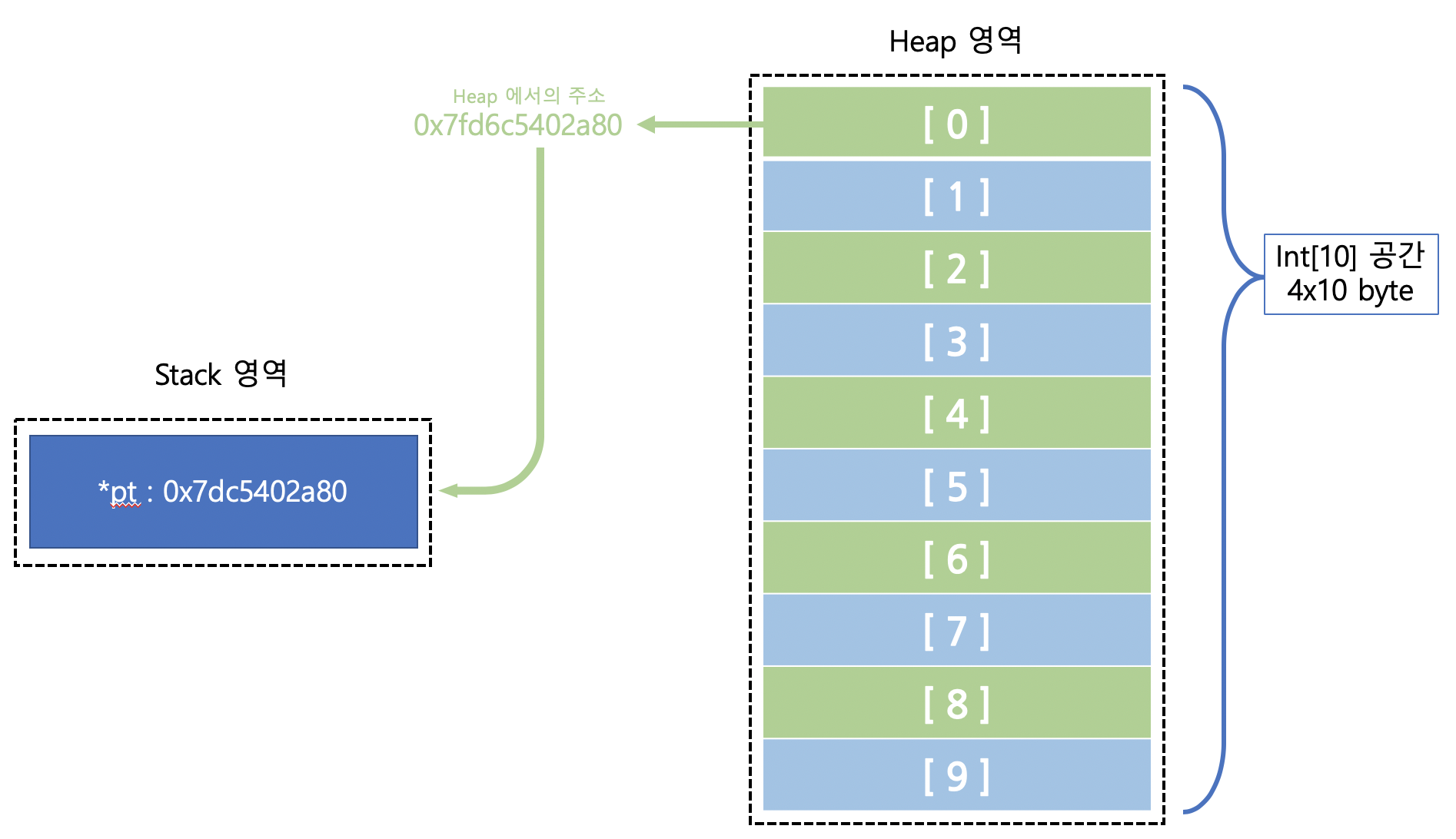
int *pt = new int[10];
위의 간단한 코드를 메모리측에서 보면 Heap영역과 Stack영역을 나눠서 봐야합니다.
앞서 다른 게시물에서 언급했듯 Heap영역은 동적할당시 사용되는 메모리 영역이며, Stack영역은 지역변수(변수,포인터, 참조자 등 모두해당됩니다.)가 사용하는 메모리 영역입니다.
따라서 위의 과정을 메모리 영역에서 보면 아래와 같은 모습을 볼 수 있습니다.
int *pt = new int[10] 에 대한 메모리 추상화
new int[10] 이라는 코드가 heap영역에 공간을 확보하고 해당 공간의 주소값을 반환한다고 했는데, 확인해보겠습니다.
#include <iostream>
using namespace std;
int main(void){
cout << (new int[10]) << endl;
return 0;
}
실행결과
위와같이 new 키워드의 결과를 출력하면 주소값을 반환하는 것을 볼 수 있습니다. 때문에 주소값을 저장하기 위해 포인터(*)를 사용하는 것입니다.
위에서 heap영역과 stack영역을 구분해서 말씀드린 이유가 있습니다!!
가장 중요한 이유, 그것은 stack영역에 저장되는 데이터는 함수가 종료되는 시점까지만 유효한 값을 갖습니다.(지역변수) 반면 heap영역은 할당받은 메모리를 반환할때까지 유효한 값을 유지합니다.
이에대한 두가지 예제를 보겠습니다.
첫번째는 stack 영역에 저장된 값의 주소를 반환한 경우입니다.
#include <iostream>
using namespace std;
int* func(){
int x=10;
return &x;
}
int main(void){
int *pt = func();
cout << *pt << " : " << pt << endl;
return 0;
}
경고 메시지실행결과
해당 코드를 실행하면 위와같은 [경고메시지]와 [실행결과]를 볼 수 있습니다.
다음으로는 heap 영역에 저장된 값의 주소를 반환하는 경우입니다.
#include <iostream>
using namespace std;
int* func(){
int *x = new int;
*x = 10;
return x;
}
int main(void){
int *pt = func();
cout << *pt << " : " << pt << endl;
return 0;
}
실행결과
후자에서는 [경고메시지]없이 [실행결과]를 얻을 수 있었습니다.
의문이 들 수 있습니다. [경고메시지가 출력되기는 했지만, 실행만 잘 되면 괜찮은거 아닌가요?] 라는 의문.
답은 절대로 안됩니다!
여러분이 프로그램을 설계할 때, 심심하면 한번씩 이상한 값을 출력하길 원하는게 아니라면, 절대 위와같은 경고메시지(⚠️)를 무시하시면 안됩니다.
위의 경고메시지가 발생하는 원인은 한가지 입니다.
-> 유요하지 않은 값, 즉 해당 메모리는 다른 값에 의해서 언제든지 덮에 씌워질 수 있는 상태라는 것입니다.
새로운 값이 스택영역에 저장되면 해당 공간에는 다른 값이 저장되고, 그때는 10이 아닌 다른 값을 출력할 것입니다. [경고메시지]의 출력을 제거한 상태라면 위와같은 문제로 프로그램이 꼬였을 때, 문제를 찾기도 힘들죠.
반면 후자에서 사용한 heap영역의 주소를 반환했을 때에는 함수가 종료된 후에도 [heap 영역의 데이터] 가 유효한 상태를 유지하기 때문입니다. heap영역의 데이터는 프로그램이 종료되거나, 해당 공간을 os에 반환할 때까지 유효한 값을 갖습니다.
OS로부터 할당받은 공간을 사용 후 반환, 그리고 다시 해당 값을 참조하는 것은?
이건 더 큰 문제를 야기할 수 있습니다. heap영역은 가변가능한 공간입니다. 사용하지 않을경우 OS에 반환(또는 회수)되는 공간이죠.
이렇게 반환된 공간은 다른 프로그램에 의해서 사용될 수 있습니다.
운이 나쁘다면(?) 반환된 공간을 참조함에따라 다른 프로그램이 사용중인 영역의 값을 프로그램이 요청하게되고, 이것은 운영체제의 프로세스 관리 규칙에 위배됨에따라 강제로 해당 프로그램이 종료되는 문제를 발생시킬 수 있습니다.
2. Delete 키워드에 대해서
사실 New 키워드에 대해서 자세히 다룬 덕분에 delete에 대해서는 크게 말씀드리게 없습니다.
단일 객체에 대한 할당을 제거할 시 delete를 사용하고, 배열 객체에 대한 할당 제서기 delete[]를 사용한다는 차이와 delete를 사용한 후에도 해당 영역에 대한 참조가 가능하지만, 실제로 접근하면 new키워드의 마지만 부분에서 언급했던 문제와 같은 일이 생길 수 있다는 것만 말씀드리면 될 듯합니다.
C, Java와 같은 언어에 익숙하다면 동적할당이라는 개념에 대해서 익숙하실 수 있습니다. 하지만, Python과 같은 언어에 익숙하다면 많이 생소한 개념일 수 밖에 없습니다.
동적할당의 반대는 당연히 '정적할당'이라는 것이 될 것입니다.
정적할당은 C언어에서 변수의 크기를 정하고 해당 크기만큼을 메모리에 할당하는 것을 말합니다.
int x[20];
이라는 코드는 x라는 변수에 20개의 '정수'를 저장할 수 있는 배열공간을 할당한다는 의미입니다. 이것을 정적할당이라고 합니다. 선언과 동시에 변수의 크기를 정하기 때문입니다.(즉, 컴파일되는 과정에서 변수의 크기가 결정됩니다.)
int형은 기본적으로 4Byte의 크기를 갖기 때문에 x라는 배열은 80Byte의 공간을 할당받습니다.
여기서 문제가 생깁니다. 만약 저장할 데이터가 80Byte의 공간에 다 들어가지 못한다면 어떻게 할까요?
만약 80Byte의 공간에 그 이상의 데이터를 넣게되면 프로그램은 컴파일과정에서 [Out Of Index]라는 애러를 내뱉거나, 실행과정에서 [OverFlow]라는 끔찍한 상황을 만듭니다.
이러한 문제를 해결하기 위해 등장한 것이 '동적할당'입니다.
동적할당은 컴파일 과정에서 변수의 크기가 결정되는 것이 아니라, 프로그램이 실행되는 과정에서 필요한만큼 저장공간을 할당받는 것을 의미합니다. 이때 이용하는 데이터영역을 Heap이라고 합니다.
프로그램은 실행되는 과정에서 변수에 더 큰 공간을 할당할 필요가 생긴다면, 동적으로 Heap영역에 이 변수를 위한 공간을 마련합니다. 만약 Heap영역이 부족하게된다면, 운영체제로부터 더 많은 메모리에 대해나 할당을 요청하고 운영체제가 메모리를 해당 프로그램에 할당하면 해당영역을 Heap영역으로 지정하여 변수에 더 많은 공간을 할당합니다. 이것이 동적할당의 과정입니다.
만약 운영체제가 해당 프로그램이 요구하는 만큼의 메모리공간을 할당하지 못한다면 프로그램은 데이터처리에 문제가 생기고 이에따라 애러를 발생시킬 것입니다.( = Ram 용략이 작은 경우 메모리가 터져 게임이 튕기는 이유 )
2. 동적할당의 이용 ( CPP/NewDelete.cpp )
C언어에서는 문자열을 처리하기 위해서 동적할당을 많이 사용했습니다. 하지만, C++에선 string을 정식으로 제공하기 때문에 문자열처리에서 동적할당을 사용할일이 줄었습니다. 하지만, 동시에 클래스와 객체에 대한 개념이 생기면서 이러한 new와 delete 키워드를 사용할 일 자체는 훨씬 늘었다고 볼 수 있습니다.
아직 클래스에대해서 다루지 않았지만, 쉬운 예제를 통해 어떤식으로 new와 delete 키워드가 사용되는지 알아보겠습니다.
#include <iostream>
using namespace std;
class MyClass{
public:
void out(){
cout << "MyClass -> out" << endl;
}
};
int main(){
MyClass *cl1 = new MyClass;
cl1->out();
delete cl1;
return 0;
}
실행결과
위에는 간단한 클래스와 클래스 메서드를 하나 만들고 메인함수에서 해당 클래스를 생성 및 메서드 호출의 과정을 담고있습니다.
어렵게 생각하지 말아주시고, main함수 부분에서 new를 이용하여 클래스를 생성하고 delete를 이용해서 생성한 클래스를 제거해주는 과정이라는 것만 알아주면 좋을 것 같습니다.
new와 delete 키워드는 아래와 같은 역할을 합니다.
new : Heap영역에 요청한 만큼의 동적공간을 할당합니다. (해당 공간의 주소를 반환합니다. -> 때문에 포인터로 받음)
delete : 할당받은 영역은 OS에게 반환합니다. (반환된 영역을 데이터를 참고하면 문제가 생길 수 있습니다.)
new와 delete 두 가지 모두 메모리에 공간을 할당/반환하는 역할을 하기 때문에 사용에 있어서 주의가 필요합니다.
C언어에 익숙한 사람이라면, Call-By-Value와 Call-By-Address라는 것에 대해서 들어봤을 겁니다.
이것은 함수에 전달되는 인자가 '값(Value)'인지 '주소(Address)'인지에 따라서 결정됩니다.
그럼 Call-By-Reference는? 인자가 '참조자(Reference)'인 것을 의미합니다.
Address나 Reference나 작동방식에 있어서는 큰 차이가 없다고 생각합니다.
2. Call-By-Value ( CPP/CallByValue.cpp )
Call-By-Value는 일반적으로 많이 사용되는 방식입니다.
함수의 매개변수로 값이 전달되는 것을 의미하며, 보통 반환값이 존재하거나 전역변수와 같은 값을 통제하는데 사용하는 함수에서 사용합니다.
만약 Call-By-Value로 swap함수를 만든다면 어떤 문제가 발생하는지 알아보겠습니다.
예제코드를 아래와 같이 만들어보았습니다.
#include <iostream>
using namespace std;
void swap(int x, int y);
int main(void){
int x = 10;
int y = 20;
swap(x, y);
cout << x << " " << y << endl;
}
void swap(int a, int b){
int temp = a;
a = b;
b = temp;
cout << "a : " << a << "\nb : " << b << endl;
}
실행결과
실행해보면 swap이라는 함수 내에 전달된 x와 y값은 서로 위치가 바뀌어서 20, 10의 순서로 출력이 된것을 볼 수 있습니다.
하지만, main함수에서 변수 x, y를 출력해보면 함수에 들어가기 전과 동일한 10과 20이라는 값을 갖고있는 것을 볼 수 있습니다.
이것은 메인함수에서 swap 함수로 인자를 전달할 때, x와 y라는 변수의 값(10, 20 이라는 값)만을 전달한 것이기 때문입니다.
즉, 위의 코드에서 swap(x, y)는 swap(10, 20)과 동일한 작동을 한다는 것을 의미합니다. x와 y의 주소값등은 전달되지 않기 때문에 함수 내에서 아무리 값을 변경해도 결과적으로 x와 y의 값은 변함이 없다는 것을 말합니다.
이게 Call-By-Value : 값에 의한 호출을 말합니다.
3. Call-By-Reference ( CPP/CallByReference.cpp )
다음은 Call-By-Reference에 대해서 다뤄보겠습니다. 위에서 Call-By-Value를 다뤄봤기에 쉽게 추론하실 수 있을 것이라고 생각합니다.
예제코드를 먼저 보겠습니다.
#include <iostream>
using namespace std;
void swap(int &x, int &y);
int main(void){
int x = 10;
int y = 20;
swap(x, y);
cout << x << " " << y << endl;
}
void swap(int &a, int &b){
int temp = a;
a = b;
b = temp;
cout << "a : " << a << "\nb : " << b << endl;
}
실행결과
차이는 매개변수를 참조자로 선언해 주었다는 것만 존재합니다. 즉, Reference(참조자)를 이용하여 값을 '호출'하는 것이 아니라 실제 변수를 참조할 수 있는 참조자를 '호출'하는 것 이게 Call-By-Reference : 참조에 의한 호출을 의미합니다.
어렵지 않은 내용이라고 생각합니다.
4. 특이한 참조자의 사용 ( CPP/Reference4.cpp )
이제부터는 참조자의 여러가지 특이한 케이스들을 다뤄보겠습니다.
먼저 참조자는 선언시 참조할 '변수'를 지정해주어야 한다는 특징이 있습니다.
즉, 아래와 같은 코드를 수행하면 애러가 발생합니다.
#include <iostream>
int main(void){
int &x = 20;
return 0;
}
실행결과
참조자는 항상 변수를 참조하기 때문에 정수형 데이터를 참조자의 값으로 갖을 수 없다는 내용을 갖습니다.
그런데 const라는 녀석을 만나면 문제가 해결됩니다.
#include <iostream>
int main(void){
const int &x = 10;
return 0;
}
위와깉이 코드를 작성해서 수행하면 아무런 애러도 발생하지 않습니다.
왜? 그걸 위해서는 const함수가 무엇인지를 먼저 알아야 한다고 생각합니다.
const : constant의 약자로 '상수'를 정의하는데 사용합니다. '상수'란 코드내에서 절대로 변하지 않는 고정된 값을 의미합니다.
그럼 왜 const함수를 사용하면 애러가 없는걸까요? 이것은 여기서 10이 단순한 '값'이 아닌 특별한 '데이터'가 되었다는 것이 핵심입니다.
어려운 이야기일 수 있습니다. 풀어서 말하자면, 애러가 났던 코드에서 참조자는 10이라는 값을 전달받았지만, 아래의 참조자는 '메모리상에 상수 10이라는 값을 갖은 공간'을 전달받은 것을 의미한다고 생각하시면 좋겠습니다.
같은 10이라는 값이지만, 전자는 메모리에 존재하지 않는 10, 후자는 메모리에 상수로 지정된 10이라는 값
물론 후자의 경우, 특이하게도 '변수'가 없는 참조자 형태를 갖습니다. 때문에 어떻게보면 의도하지 않은 사용이 될 수도 있습니다.
하지만 덕분에 아래와 같은 코드를 사용도 가능해졌습니다.
#inlcude <iostream>
using namespace std;
int sub(const int &x, const int &y){
return x-y;
}
int main(void){
int result = sub(10,5);
cout << result << endl;
return 0;
}
5. 참조자의 문제점
편리한 참조자가 무슨 문제를 갖고있는가? 이것은 맨 처음에 다뤘던 swap코드를 다시 한번 보며 말씀드리겠습니다.
#include <iostream>
using namespace std;
void swap(int &x, int &y);
int main(void){
int x = 10;
int y = 20;
swap(x, y);
cout << x << " " << y << endl;
}
void swap(int &a, int &b){
int temp = a;
a = b;
b = temp;
cout << "a : " << a << "\nb : " << b << endl;
}
만약 위와같은 코드가 존재할 때, main함수 부분만은 보고 x, y 값이 [ Call-By-Reference ]라는 것을 알 수 있습니까?
swap함수를 정의한 것을 보지 않는다면, 메인함수에서는 해당 함수가 Call-By-Reference인지 Call-By-Value인지 알 수 없습니다.
큰 문제가 아니라고 생각할 수 있지만, 여러사람이 한 코드를 공유한다면 이것은 큰 문제가 될 수 있습니다.
당연히 Call-By-Value라고 생각하고 사용한 함수가 Call-By-Reference였고, 이에따라 함수의 인자로 전달한 값이 변하게되는 문제가 발생할 수 있습니다.
위의 4개만 알고있다면 포인터를 쉽게 사용은 못해도, 포인터를 이용한 다양한 알고리즘, 자료구조들을 이해하는데는 충분합니다.
2. 참조자 ( CPP/Reference1.cpp ~ Reference3.cpp )
그럼 본론으로 돌아가서 C++의 참조자에 대해서 언급해보겠습니다.
위에서 보았듯이 C++에서도 C언어와 마찬가지로 포인터(*)를 사용할 수 있는 것을 볼 수 있었습니다. 하지만, 프로그래밍을 할 때, 포인터를 사용한다는 것은 익숙하지 않은 프로그래머에게는 상당히 부담스러울 수 있는 일입니다.(난이도 때문)
이러한 문제 때문이었는지 C++에서는 '참조자'라는 특별한 친구를 만들어 주었습니다.
참조자는 변수에 대한 별명을 만들어주는 것이라 볼 수 있습니다.
예제 코드 몇개를 살펴 보겠습니다.
#include <iostream> // CPP/Reference1.cpp
using namespace std;
int main(void){
int x = 10;
int &y = x; // int y = x 사용시 결과는 11, 11
x++;
y++;
cout << x << endl;
cout << y << endl;
return 0;
}
실행결과
만약 [ int y = x ]라고 해주었다면, 결과는 11, 11이 출력되었을 것입니다.
왜냐하면 변수라는 것은 [ 데이터 ]를 저장하는 공간이기 때문입니다. 데이터, 즉 값이라는 것을 저장하는 변수는 특정한 숫자나 특정한 문자열을 저장할 뿐이지 다른 변수의 주소값등을 저장하지는 못합니다.
따라서 위의 코드에서 [ int &y = x ]라는 부분이 특별한 기능을 한다는 것을 알 수 있습니다.
변수 선언과정에서 변수명 앞에 '&' 를 붙일 경우, 이것은 변수가 아닌 '참조자'라는 것으로 선언되었다는 의미를 갖습니다.
참조자는 위에서 언급한것과 같이 '변수'에 대한 '별명'을 붙여준다는 것을 말합니다.
위의 예제를 조금 수정해서 아래와 같이 실행해 보았습니다.
#include <iostream> // CPP/Reference2.cpp
using namespace std;
int main(void){
int x = 10;
int &y = x;
int &z = y;
cout << &x << endl;
cout << &y << endl;
cout << &z << endl;
return 0;
}
실행결과
위의 코드를 보게되면 '변수x'와 '참조자y'는 동일한 주소값을 갖고있는 것을 볼 수 있습니다.
그림으로 그려본다면 아래와 같은 모습임을 예측할 수 있습니다.
중요한것은 [변수x]와 [참조자 y, z]가 존재하는 형태라는 것입니다.
여러개의 변수가 하나의 데이터 공간을 공유하는 것은 아니라는 것을 꼭! 기억했으면 좋겠습니다.
( y 나 z가 없는 x는 존재할 수 있지만, x가 없는 y 또는 z 는 존재할 수 없습니다.)
참조자가 어떤 것인지는 대충 아셨을 것이라고 생각합니다. 그럼 이제 참조자가 어떤식으로 사용되는지 알아보겠습니다.
참조자의 가장 큰 특징은 딱 두가지입니다.
참조자는 선언과 함께 참조할 변수가 정해져야 합니다. ( int &x; 와 같이 선언 불가)
참조자는 함수 호출시 매개변수로 갖을 수 있다.
제가 설명력이 부족해서 이해하기 힘드실테니, 예제코드를 통해서 알아보겠습니다.
#include <iostream>
using namespace std;
void swap(int &a, int &b);
int main(void){
int x = 10;
int y = 20;
swap(x,y);
cout << x << endl;
cout << y << endl;
return 0;
}
void swap(int &a, int &b){
int temp = a;
a = b;
b = temp;
}
실행결과
일반적으로 swap 함수를 사용할 경우 포인터를 사용해주었었습니다. 왜냐하면 함수의 경우 일반적으로 [Call-By-Value]를 원칙으로 하기 때문입니다.
( Call-By-Value, Call-By-Reference 에 대한 내용은 다음페이지에서 다루겠습니다. )
위의 swap 코드를 보게되면 [ int &a, int &b ]의 형태로 '참조자'를 이용한 것을 볼 수 있습니다.
따라서 이 swap 함수에서의 a, b라는 값은 메인함수의 [ x, y ]라는 변수의 '별명'이 되는 것을 볼 수 있습니다.
여기서 혹시 [ int &a ] 형태로 참조자는 선언할 수 없냐고 했는데 사용가능한건가? 하는 의문이 있을 수 있습니다.
결과는 당연히 가능합니다. 왜냐하면 함수의 매개변수는 함수가 코드내에서 실행되는 순간 할당되기 때문입니다.
위의 함수를 '인라인' 된것처럼 본다면 다음과 같은 코드가 될 것입니다.
#include <iostream>
using namespace std;
int main(void){
int x = 10;
int y = 20;
// Swap 함수 영역 시작
swap(int &a = x, int &b = y){
int temp = a;
a = b;
b = temp
}
// Swap 함수 영역 끝
cout << x << endl;
cout << y << endl;
return 0;
}
'실제 코드가 아닌 추상적인 코드입니다'
위와같이 함수는 실행되는 과정에서 각각의 매개변수에 값을 할당하기 때문에 참조자만을 선언하는 것이 아니라는 것을 알 수 있습니다.
참조자는 정말 중요한 개념이고 다양한 응용이 있기 때문에 다음 페이지에서 조금 더 알아보도록 하겠습니다.