CNN 기초정리
원래는 mnist 데이터를 다루려고 했는데, 그래도 CNN 기초정리는 해야겠어서 잠깐 살짝 다루고 넘어가겠습니다.
0. 시작 전에
CNN에 대해서 깊게 설명하려면 일단 기존 DNN의 개념부터 시작해야 해서 아주~ 가볍게 설명하고 넘어가겠습니다.
혹시 추가 질문이나 문제 있는 부분은 글 남겨주세요~
1. CNN이란?
Convolutional Neural Network의 약자로 일반 Deep Neural Network에서 이미지나 영상과 같은 데이터를 처리할 때 발생하는 문제점들을 보완한 방법입니다.
어떤 문제가 있었나?
DNN은 기본적으로 1차원 형태의 데이터를 사용합니다. 쉽게 생각하면 iris데이터를 생각해보시면 됩니다.(다뤄보지 않았다면... 크흠...)
iris데이터를 보게 되면 Columns으로 꽃받침과 꽃잎의 길이 등이 데이터로 오게 되는데 아래와 같습니다.
| Index | 꽃받침길이 | 꽃받침너비 | 꽃잎길이 | 꽃잎너비 | 꽃의종류(Target) |
| 1 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
이러한 형태의 데이터가 많이 존재하는데, 여기서 꽃받침과 꽃잎의 정보를 input데이터(=X)로하고, 꽃의 종류를 output데이터(=Y)로 설정하여 학습을 하게 됩니다
그리고 학습된 모델에게 꽃받침과 꽃잎에 대한 정보를 넣음으로 꽃의 종류를 맞추게 하는 모델이 되게 됩니다.
Iris 데이터에 대한 설명은 여기까지이고, 이러한 데이터를 1차원 데이터라고 부르는 이유는 데이터가 하나의 row로 표현되기 때문입니다.
하지만, 이미지는 어떤가요? 480x480 같은 형태로 표현되는 이미지는 하나의 row로 표현되지 않습니다. 물론 한 줄로 표현할 수는 있겠죠. 다만, 이미지 데이터를 하나의 row로 변환하게 되는 순간, 데이터는 큰 손실을 갖게 됩니다.
예를 들어 아래와 같은 강아지 사진이 있다고 봅시다.

이런 사진 데이터를 한 줄로 표현한다면...?
아래와 같은 한 줄이 됩니다... 위에서부터 1px씩 잘라서 우측에 붙이는 형태죠.

실제로는 더 작은 숫자들의 집합으로 이루어진 한 줄 데이터가 되겠지만, 의미적으로 봐주세요.
저 한 줄로 표현된 이미지와 기존의 이미지를 비교해보면 DNN으로 이미지를 학습시킬 때의 문제를 알 수 있습니다.
이미지 데이터는 한 점을 기준으로 그 주변 점들이 모여 하나의 객체(?)가 됩니다.
위 이미지에서 보면 이미지의 특정 픽셀(이미지 데이터에서 매우 작은 한 점)들이 모여 강아지라는 객체를 만들게 되는데, 한 줄로 된 row데이터에서는 이러한 연간 관계가 제거된다는 문제가 있습니다.
말료표현하기 어렵네요...
그럼 CNN에서는 어떻게 극복했을까?

제가 설명하기 좋은 자료를 찾기가 힘들어서... 대충 그렸습니다... ㅋㅋ
위와 같은 이미지가 있다고 생각해봅시다. 다음에 작업할 데이터도 숫자 이미지니 까요.
이 이미지는 더 자세하게 보면 아래와 같은 상태로 볼 수 있습니다.

위의 이미지의 빨간색 네모칸 하나를 1픽셀로 생각해주시고, 한 픽셀에는 흰색 또는 회색이 들어있다고 생각해주세요.
(네모칸에 회색 또는 흰색 중 많이 차지하는 녀석이 들어있다고 가정해주세요.)
위와 같은 이미지에 회색이 들어있는 픽셀은 숫자로 1이 들어있고, 흰색에는 0이 들어있다고 생각해봅시다. 그럼 아래와 같은 그림이 됩니다.
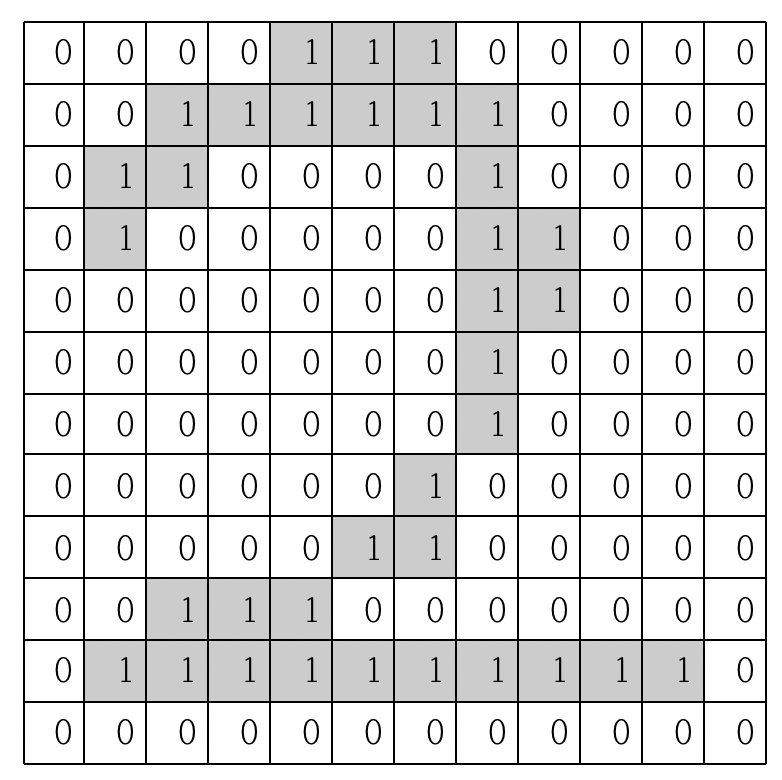
모든 이미지들은 기본적으로 위와 유사하게 표현됩니다. 물론 포맷(압축) 방식에 따라서 차이가 있겠지만, 우리가 다루는 대부분의 이미지는 1개의 픽셀이 RGB를 의미하는 3개의 색상 값을 갖고 있어서 이 값을 통해서 1픽셀의 색이 결정되는 형태입니다.
(즉, 한 개 픽셀도 3개의 차원으로 구성된다는 것이죠...;; 지금은 간단히 0 또는 1의 값이 있다고 합시다. 자세한 건 나중에)
CNN에서는 이 이미지의 한 픽셀과 주변 픽셀들의 연관관계를 유지시키며 학습시키는 것을 목표로 합니다.
CNN은 일단 하나의 이미지로부터 픽셀 간의 연관성을 살린 여러 개의 이미지를 생성하는 것에서 시작합니다.
방법은 아래와 같습니다. 3x3의 크기로 이미지를 뽑아내서 마찬가지로 3x3크기의 랜덤값을 갖고 있는 데이터와 각 픽셀을 곱해서 더해줍니다.
이때 랜덤값을 갖고 있는 3x3데이터를 필터라고 부릅니다.

계산해보면 각 필터의 값에 따라서 4, 15, 12와 같은 서로 다른 값이 발생하는 것을 알 수 있습니다.
즉, 9개의 픽셀로부터 1개의 값이 생성되며, 빨간색 칸을 한 칸씩 옮겨가며 이 값들을 하나씩 생성하게 되면 12x12 이미지에서 필터 하나가 10x10 크기의 이미지를 생성하게 됩니다.
(빨간색이 1칸씩 움직이지 않게 할 수 도있습니다. strides라는 값을 통해서 이것을 설정할 수 있습니다.)
필터가 3개라면 10x10 이미지 3개가 생성되겠죠.(이미지의 각 픽셀에는 계산된 값이 들어갑니다.)
그럼 12x12 이미지가 10x10으로 줄어드는데 괜찮은 건가?라는 의문이 들 수 있습니다.
이에 대해서는 확실하게 문제다! 문제가 아니다!라는 확실한 그건 없습니다만, 추측하기에 어쨌든 손실되는 부분이 발생한다고 생각하는 경우가 많기 때문에 이러한 문제를 해결하기 위해서 padding이라는 값을 주게 됩니다.
padding이란 원래 이미지의 양옆에 0 값을 갖는 데이터를 추가하여 위와 같은 방법을 취한 후에도 원래의 크기와 동일한 이미지를 유지하도록 해주는 방법입니다.
이러한 일련의 과정을 CNN에서는 Convolution이라고 합니다. CNN의 핵심에 해당하는 부분이죠.
Convolution이 CNN의 한 부분이라면, 그 외의 부분도 있겠죠?
Pooling이라는 녀석과, Flatten이라는 과정이 존재합니다.
Pooling?
Pooling은 CNN의 문제점 중 하나를 교정해주는 작업입니다.
CNN의 문제점... 시작하자마자 문제네요...
위에서 Convolution이라는 과정을 통해서 많은 수의 이미지를 생성한 것은 좋은데... 너무 많아졌다는 게 문제입니다.
하나의 이미지에서 Convolution이라는 과정을 거칠 때마다 5배씩 이미지가 생성되는데, 이미지의 크기도 줄지 않고...
그래서 도달한 게 Pooling이라는 과정입니다.
이미지를 분석하는 데 있어서 과연 Null 값과 유사한, 즉 correlation이 낮은 영역은 없을까? 하는 의문이 들지 않나요?
사실 존재 여부를 떠나서 사람이 그것을 판단하는 건 쉽지 않은 일입니다.
따라서, Convolution과 유사한 과정인데, 이미지를 5배씩 뻥튀기시키지 말고, 1개의 이미지에 1개의 출력을 만들면서 동시에 기존 이미지에 Padding 없이 Filter만 적용해서 크기를 줄이는 방법을 Pooling이라고 합니다.
Flatten은?
간단합니다. 아래를 봐주세요.
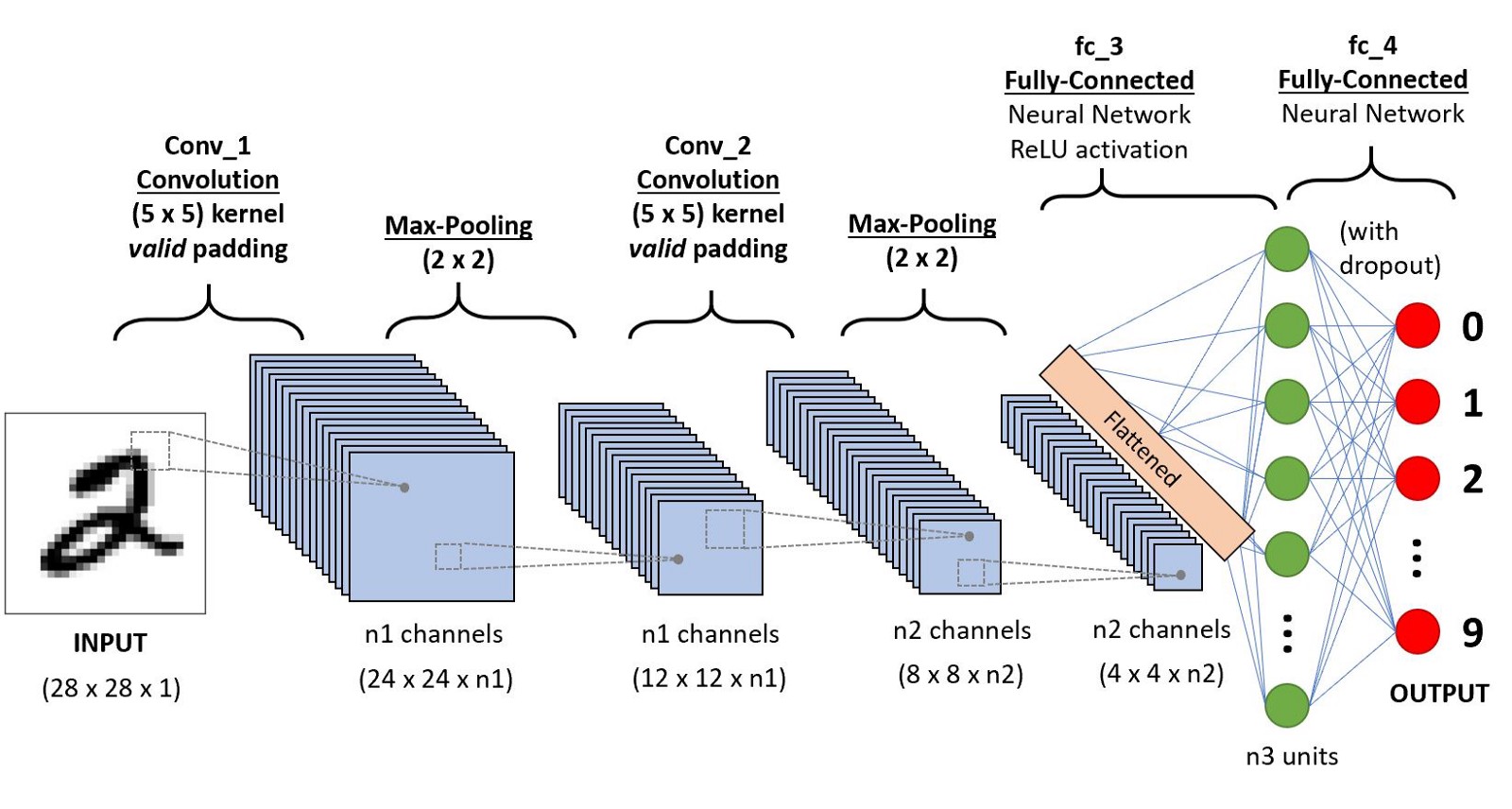
대충 전체적인 느낌이 오시나요?
Colvoltuion과 Pooling을 반복해주면 이미지의 숫자는 많아지면서 크기는 점점 줄어들게 됩니다.
이것은 최종적으로 도출된 nxn이미지는 이미지라는 의미보다는 특정 이미지에서 얻어온 하나의 특이점 데이터가 된다는 것입니다.
그 말 곧, 이것은 2차원이 아닌 1차원의 Row 데이터로 취급해도 무관한 상태가 된다는 의미이기도 합니다.
따라서 하나의 이미지로부터 다양한 특이점들을 뽑아내고 이것을 1차원의 데이터로 변형하는 것 이게 Flatten입니다.
위의 이미지를 보면 이해하실 수 있습니다~~!!! 제발...
Flatten과정을 거치면 이후에는 그냥 DNN과 동일하게 만들어진 네트워크를 통해서 Output을 출력하게 됩니다.
간단한 듯 아닌듯하죠?
아직은 어렵지만, 이다음에 Tensorflow와 mnist 데이터를 이용해서 분석하는 실전으로 한번 더 복습하면 됩니다.
'머신러닝 > CNN' 카테고리의 다른 글
| [딥러닝 CNN] 3. mnist데이터 CNN으로 조지기(with, Keras) (0) | 2019.06.26 |
|---|---|
| [딥러닝 CNN] 2. mnist데이터 CNN으로 조지기(with, Tensorflow) (0) | 2019.05.31 |