Keras로 조지는 편은 다음에 이어서 올리겠습니다.
TensorFolw와 CNN 모델로 Mnist데이터 학습시키기
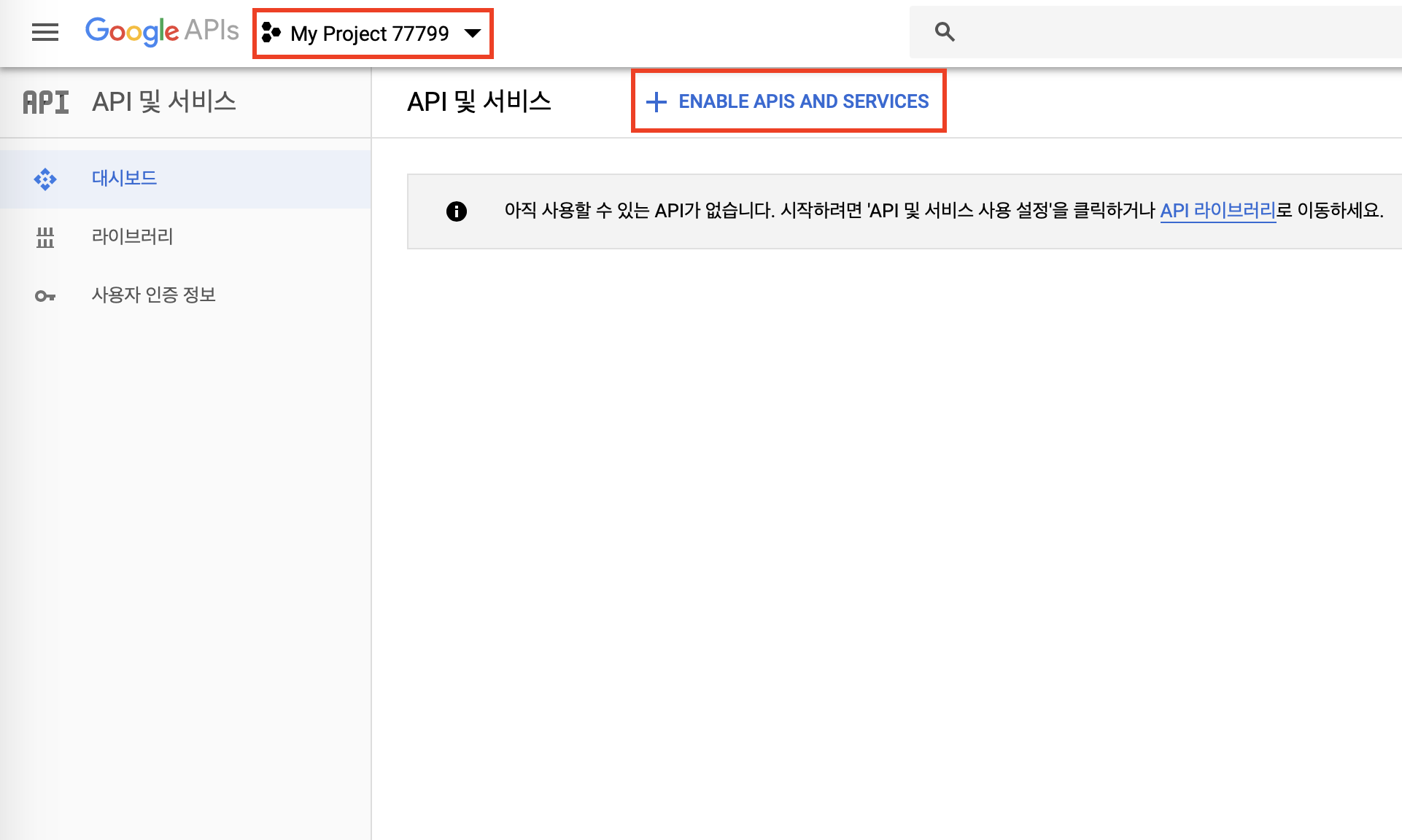
0. 시작전에
- TensorFlow 설치와 Keras설치에 관한것은 여기서 다루지 않습니다.
- CNN에 대한 부분은 이전 게시글을 참고해주세요.
- Keras만 갖고놀다가 TensorFlow를 잡으니 Python하다가 C언어하는 느낌이네요.
- CNN으로 조지기라고 적어두고, 내가 조져진 게시물...
1. 데이터 다운로드
일단 시작은 기본 라이브러리 호출과 데이터 다운로드부터 시작하겠습니다.
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./data/", one_hot=True)TensorFlow는 tf라는 이름으로 불러와주었습니다.
그리고 위와같은 방법으로 데이터를 다운로드해서 mnist라는 변수에 담아주었습니다.
<주의>
위와 같이 코드를 실행하면 현재 파이썬파일과 함께있는 data라는 폴더에 mnist파일이 저장됩니다. data라는 폴더가 없을 경우 애러가 발생할 수 있습니다.

위와같이 해당 코드를 실행하면 4개의 파일이 data의 폴더에 저장됩니다.
2. 데이터 확인하기
mnist 데이터를 보게되면 아래와 같이 "test", "train", "validation"이라는 3개의 데이터셋이 존재하는 것을 볼 수 있습니다.
- TRAIN DATA : 학습을 시키는 용도의 데이터
- VALIDATION DATA : 학습시킨 모델을 검증하는 데이터
- TEST DATA : 최종적으로 학습시킨 모델이 판단할 데이터
Validation은 최종적으로 Test데이터를 통해서 결과를 도출하기전에 최종적으로 확인하는 용도라고 생각해주시기 바랍니다.
그럼 mnist.train 이하에는 어떤 데이터가 있는지 확인해보겠습니다.

위와깉이 몇개의 데이터가 보이는데 중요한건 "images"와 "labels"라고 할 수 있습니다.
실제 학습시킬 데이터와 그 정답이니까요.
한번 출력해서 확인해보겠습니다.

먼저 labels 부분의 5번째 데이터를 보게되면 9번째 자리에 1이 표시되어있는 것을 볼 수 있습니다.
이러한 형태를 One-Hot이라고해서 오로지 특정 위치 하나에만 1이 존재함으로 그 자리의 값을 특정하는 것을 말합니다.
위의 경우 맨 앞이 0, 마지막이 9가 되는 형태고 9번째 자리가 1인것을보면 Label은 8을 의미하고 보이시는 것 처럼 이미지도 8을 띄우고 있습니다.
다음으로 데이터의 크기를 확인해보겠습니다.

label은 0~9까지 10개의 자리를 차지하기 때문에 10으로 나눠준 값이 총 이미지의 갯수라고 볼 수 있습니다.
- train : 55000개
- validation : 5000개
- test : 10000개
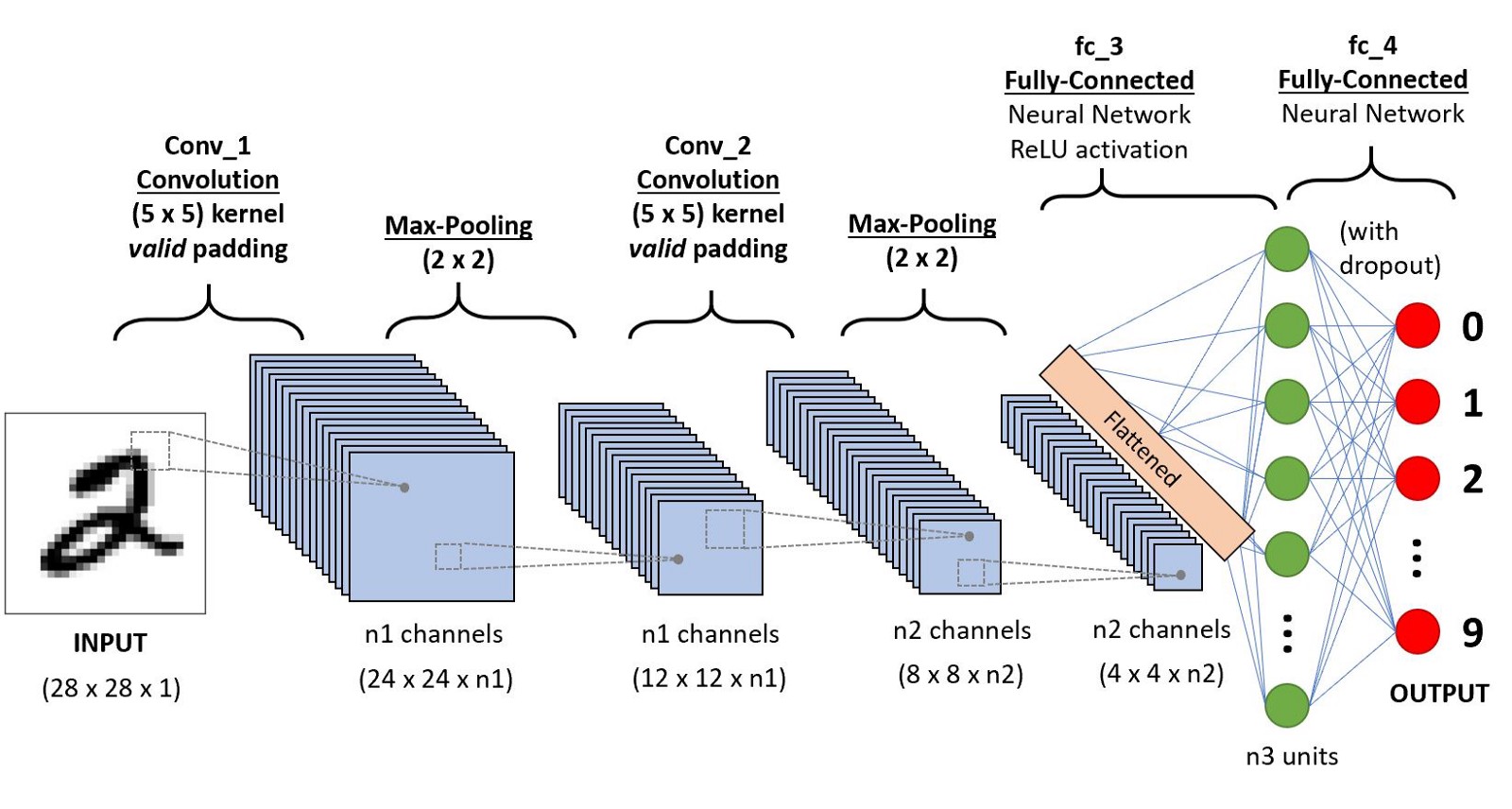
3. 모델 구축하기
tf.set_random_seed(777)
learning_rate = 0.001
training_epochs = 10
batch_size = 100
X = tf.placeholder(tf.float32, [None, 784])
X_img = tf.reshape(X, [-1, 28,28, 1])
Y = tf.placeholder(tf.float32, [None, 10])일단 위와같이 초기상태를 만들어주었습니다.
placeholder는 사용자와 모델간의 데이터 이동이 가능한 변수(?)같은 녀식입니다.
X 는 이미지데이터가 들어갈 공간입니다. mnist데이터는 2차원 이미지가 1차원 형태로 되어있습니다. (...;;)
그래서 784크기의 이미지가 X에 들어간 후 reshape를 통해서 28x28의 형태로 변형시키는 과정이 필요합니다.
또한 최종적으로 출력되는 Y는 One-Hot출력되기 때문에 10개의 공간을 설정해주었습니다.
W1 = tf.Variable(tf.random_normal([3, 3, 1, 32], stddev=0.01))
L1 = tf.nn.conv2d(X_img, W1, strides=[1, 1, 1, 1], padding="SAME")
L1 = tf.nn.elu(L1)
L1 = tf.nn.max_pool(L1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
# 14 x 14
W2 = tf.Variable(tf.random_normal([3, 3, 32, 64], stddev=0.01))
L2 = tf.nn.conv2d(L1, W2, strides=[1, 1, 1, 1], padding="SAME")
L2 = tf.nn.elu(L2)
L2 = tf.nn.max_pool(L2, ksize=[1, 1, 1, 1], strides=[1, 1, 1, 1], padding="SAME")
# 14 * 14
W3 = tf.Variable(tf.random_normal([3, 3, 64, 128], stddev=0.01))
L3 = tf.nn.conv2d(L2, W3, strides=[1, 1, 1, 1], padding="SAME")
L3 = tf.nn.elu(L3)
L3 = tf.nn.max_pool(L3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
# 7 * 7
L4_flat = tf.reshape(L3, [-1, 7*7*128])
그리고 대충 Convolution과 Max_pooling을 반복하는 구조를 대충 만들었습니다.
W(Weight)의 stddev는 랜덤한 값의 설정할 때의 표준편차입니다.
conv2d는 2차원 이미지에대한 Convolution을 의미합니다.
Padding = "SAME"은 입출력 이미지의 크기가 동일하다는 것을 말합니다.
Activation Function은 elu로 설정해주었습니다.
그냥 별생각없이 대충 만들어봤습니다. mnist데이터 자체가 간단한 데이터라 아마 잘 될꺼라는 믿음...으로 만들었습니다.
(gpu환경이 아니시고 컴퓨터의 사양에 자신이 없으시다면 절절하게 조정이 필요합니다.)
최종적으로 3개의 Conv와 Pooling 후 Flatten 과정을 수행하게됩니다.
이제 일반 DNN형태를 만들겠습니다.
hidden1 = tf.layers.dense(L4_flat, 300, name="hidden1",activation=tf.nn.elu)
hidden2 = tf.layers.dense(hidden1, 100, name="hidden2",activation=tf.nn.elu)
logits = tf.layers.dense(hidden2, 10, name="outputs")이것도 뭐... 간단하게 만들어봤습니다.
아마 잘 될꺼라는 믿음으로...
중간 숫자 300, 100, 10은 출력의 갯수를 말합니다.
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits, labels=Y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for epoch in range(training_epochs):
avg_cost=0
total_batch = int(mnist.train.num_examples / batch_size)
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
feed_dict = {X:batch_xs, Y:batch_ys}
c, _ = sess.run([cost,optimizer], feed_dict=feed_dict)
avg_cost += c / total_batch
print("Epoch : ", "%04d" % (epoch + 1), 'cost = ', '{:.9f}'.format(avg_cost))
print("Learning Finished!")마지막으로 학습과정입니다.
저 코드를 직접 짠 기억은 없는데, 저장된 자료들중에 mnist 관련자료에 있어서 갖고왔습니다...
(아마 sung Kim님의 코드가아닐까합니다... 존경합니다.)
scoftmax cross entropy에 Ver2가 생겨서 적용해봤습니다.
Cost Function은 reduce mean을 사용했습니다.
optimizer는 가장 배신을 덜하는 Adam을 사용했습니다.
4. 학습

10Epoch에 cost가 0.01정도까지 떯어지네요. 일단 흠...
좋습니다. 테스트해서 어느정도 결과가 나오는지 확인해보겠습니다.
corrent_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(corrent_prediction, tf.float32))
print("Accuracy: ", sess.run(accuracy, feed_dict={X : mnist.test.images, Y : mnist.test.labels}))
실행결과 99%확률로 맞추네요~
잘맞추네요...;;
sess.close()
tf.reset_default_graph()끝나면 위의 코드를 실행해서 초기화시켜주세요.
역시 Keras가 쉽습니다...;;
'머신러닝 > CNN' 카테고리의 다른 글
| [딥러닝 CNN] 3. mnist데이터 CNN으로 조지기(with, Keras) (0) | 2019.06.26 |
|---|---|
| [딥러닝 CNN] 1. CNN이란? (5) | 2019.05.30 |